
前言:本文记录了本菜狗做ysyx流水线章节的经历和每日debug经历和吐槽,水平有限,谨慎参考
Cachesim:dcache

为了引出流水线,还让我先评估但是感觉很不自然,我都知道这一节课是流水线了,这种还有必要吗
但是为了我的cachesim的完整性,我会去做这个
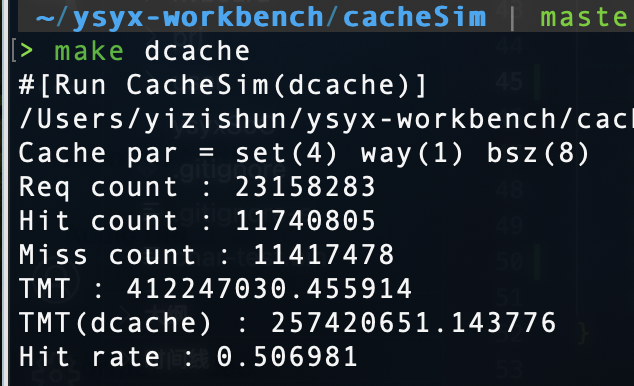
同样的参数,dcache命中率很低,加之访存指令不多,以如此多的面积获得并不多的性能提升,确实没啥必要(没有dache时访存大概在3.5亿周期,有dcache访存大概在2.7亿周期,再加之dcache更复杂的逻辑,确实完全没有必要)

我相信流水线可以让我的core快很多的😘😘
简单流水线处理器

感觉这个任务跳的有点快,我觉得还可以做一些任务的分解
不处理任何冒险的流水线处理器
我觉得第一步是将多周期改成流水线
以下是我的探索路径,可能完全错误,请不要参考
我的in out其实在多周期已经写的很好了,但是,总有一些东西感觉没有被节藕,就是这个pc值,下一个pc值会在三个阶段计算出来,IF(pc+4),ID(mepc,mtvec),EX(pc+imm,pc+rs2),会导致IFU,IDU,EXU存在耦合,导致我有点难受
回去看看cpu设计实战,我记得有一个pf阶段的,看我能不能拆一个出来
cpu设计实战讲的很简略我觉得
我现在的思路是将IFU拆开,一部分专门用来取指,一部分专门用来计算pc,我就将专门用来计算pc的叫做pf好了,pf给if一个valid信号,if和pf握手,收到pc后进行axi的操作,而pf应该保持valid一直为1,以保证if能不断工作
我忽然产生一个疑问,如果下游模块始终没有置ready,那上游模块是保存输出值,继续工作,还是停止工作,直到下游握手,我觉得这个问题似乎是这个上游模块的输出FIFO深度的问题,上游工作完,将结果放入FIFO,然后继续工作,所以停止工作其实是FIFO是1的特殊情况,但是如果放FIFO的话,相当于下游有一个流水间寄存器,上游还有,这会导致面积开销很大,所以我决定还是等待吧
使用一个pf阶段一是可以保证将pc的计算节藕,使得IFU,IDU,EXU,LSU,WBU都是简单的单向传输,第二个优点是由于取指是一个不知道多少个周期的操作,通过节藕,可以保证pc的更新是时刻正确的(即确实是pf给的,如果pf还没有选择出nextpc,valid信号置0)
(甚至还有的操作是让pf来掌管axi的ar通道,ifu来掌管r通道,但是我现在暂时不打算实现这个(这个确实会快一个周期,感觉很有性价比的,我看了一下,有2亿条指令,每一条快一个周期,就是快2亿个周期(虽然总周期是52亿。。。)))
讲义给了一个pipplineconnect函数,至于具体最后一个怎么写我就不说了,但是应该是有一个坑的,但是我发现我没有用thisOut,这个东西的意义是什么
通过这个信号可以为模块隐藏流水线寄存器的细节,只要模块从类似idle的状态转移,到下一次握手之前,都可以认为in信号的valid的,好漂亮的实现方式
之后是实现pf,输入是if,id,ex的pc值,输出是计算出来的nextpc,理应当取exu的pcsrc信号来进行选择,这样不会出现控制冲突,既然我打算先不考虑冲突,那我就打算就这样做(虽然这样做pf获取下一个pc的效率会降低很多,但是先完成后完美啦)
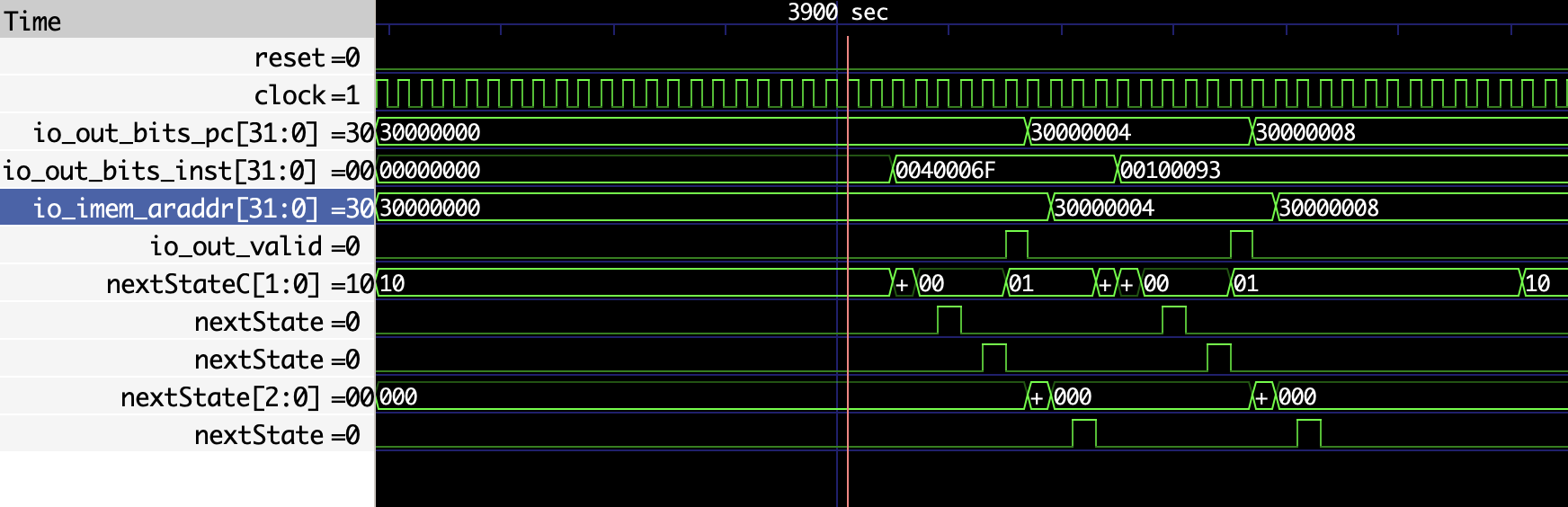
感觉也算是流起来了?感觉cache hit的时候需要六周期,感觉好久啊,如果是六周期,那我甚至都无需解决各种冲突了…..
让我分解一下这六个周期分别是什么
我的delay寄存器占了三个周期(就是一个远古任务,“添加LFSR”)我做了一个conf选项拿掉这个寄存器
去掉了还剩三个周期,分别是各个通道的握手状态转移,流水线寄存器还会导致下游模块获得信号慢一个节拍
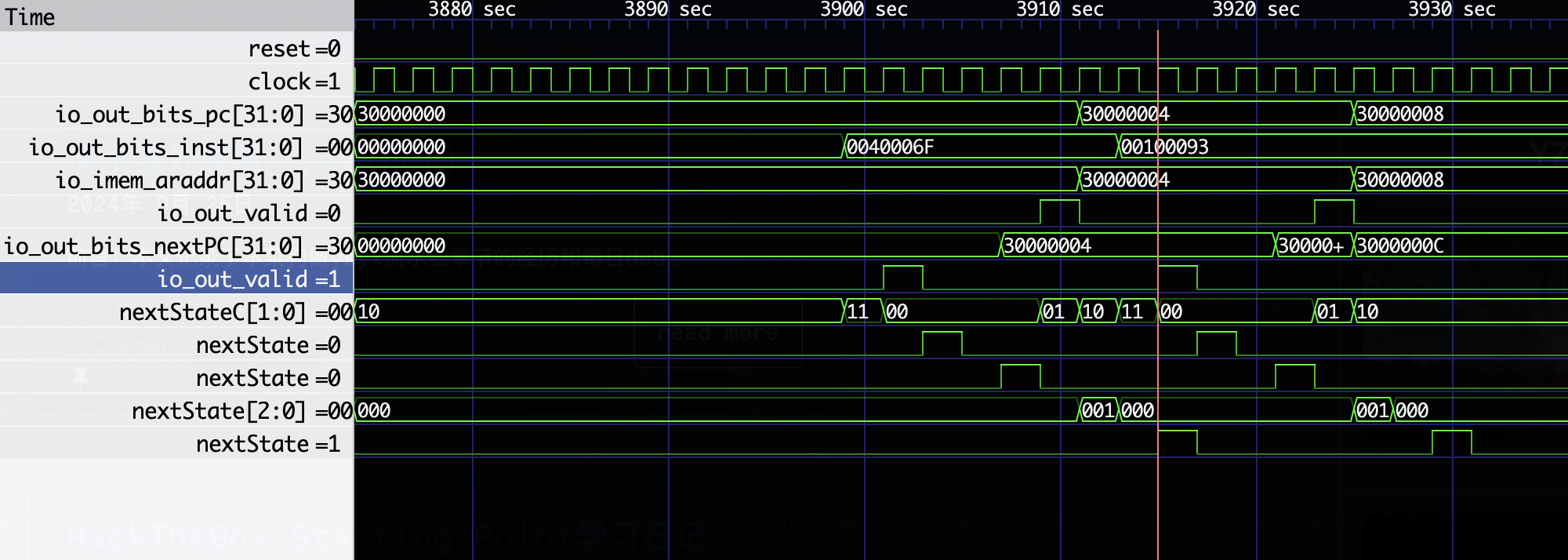
axi信号至少要2个通道握手,ar和r(参见我soc章节的第一个bug,rready不能在ar通道未握手之前置1),再加上模块之间的状态转移,感觉暂时没有什么优化的想法了(详细的说一下,01对应pf和if的fire,10对应ar的fire,11对应r的fire,00对应if和id的fire)诶,我忽然好想有一个想法,就是01和10能不能重合一下,就是之前说的pf管ar通道,if管r通道
感觉我需要重写很多,并不是很难就是很麻烦,因为我需要把我的axi类拆开,然后就需要改动很多代码
我觉得我压缩一下这个状态机,可以缩减到两个周期,第一个周期发addr,第二个周期获得data,第二个周期顺便把out.valid置1,哎,感觉实践起来还是困难的
我看之后有个任务是增加hit时的速度,似乎就是解决这个问题的,我到时候再来解决这个问题(看了一下似乎还能让icache流水化)那我在这里插个眼
加了流水间寄存器,面积飙到了3.669w,流水间寄存器占了约8k面积,但是频率312->468,还是很舒适的(我看了一下,关键路径是exu流水间寄存器->pf->pc寄存器,组合逻辑就大概是exu+pf的延迟,exu大概1.738,pf大概0.3)
还是跟之前一样,暂时不做任何优化(随手做了一个优化(把pc+4的信号从流水间寄存器删掉了),变成3.54w了,频率变成501了,舒服)
忽然发现其实我的状态机理解的不对(因为明天预学习答辩,但是我是面试别人的人(志愿者),所以我在复习状态机的定义的时候发现我写的状态机特别诡异,我状态机的转移依赖于输出…..,输出又依赖于状态机,具体表现为我是在握手fire的时候做状态转移,这样我必须寄存我的输出,让状态机的转移依赖于上一次被计算出来的输出),其实这是我做总线时的错误理解,我需要重构修改一下我的状态机代码
让我再理解理解moore和mearly的区别,moore时输入改状态,输出取决于状态,导致输入输出完全被隔离一个周期,mearly就是输出取决于输入,换句话说输出取决于nextstate(就是我现在写的),moore状态机会比mearly慢一个周期,但是(我感觉)输入逻辑输出逻辑被寄存器切分,频率会更高
moore比mealy状态划分更多的原因是由于moore的输出完全取决于状态,使得每一个特定的输出组合都需要一个状态,而mealy则不用

改完之后把状态机压缩了一下,现在舒服了,但是由于我改状态机需要测试一下访存,所以很自然的引出了结构冒险
改完还进行了一次综合和时序分析,34585.054,354.226MHz???为啥频率掉这么多 ,我急需看一下关键路径,哦,我知道了,由于我改了状态机后,ifu能做到第一周期发地址,第二周期出结果,关键路径没有被寄存器切割,icache部分进入了之前的关键路径中(可以发现面积变小,我估计就是寄存器减少的缘故),让我想想
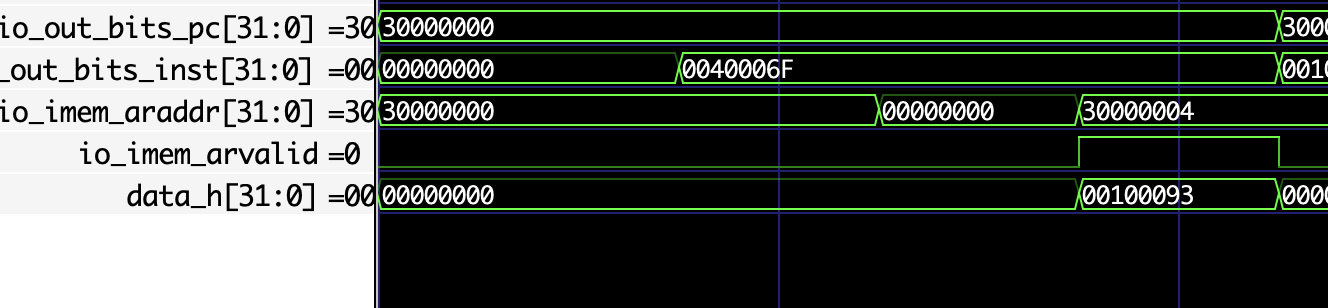
其实icache读出数据是一周期的事情,就是第一周期给地址,当前周期返回数据,中间其实没有寄存器的,所以关键路径是在exu->idupc->pfu->ifu->icache_ext->imem_rdata寄存器,中间没有任何寄存器,所以需要在ifu.io.imem.araddr和icache中间加一个寄存器,我忽然觉得ifu和icache中间真的有必要用axi总线连接吗,既然icache可以在一个周期读出来,但是我现在ifu其实也是两个周期读出内容,所以其实可以无痛改一下的,甚至可以减少某些数据通路的开销(但是其实我的chisel把这些不用的信号优化掉了)
经过对icache状态机的一阵优化,并且在ifu和icache中插入了一个寄存器,最终面积31811.738000,频率499
解决结构冒险

我个人偏向让IFU等待LSU,因为假如让LSU等IFU,就有可能存在LSU被饿死的情况
解决了结构冒险之后,顺手重构了一番xbar,现在面积29971.018000,频率不变499
解决数据冒险
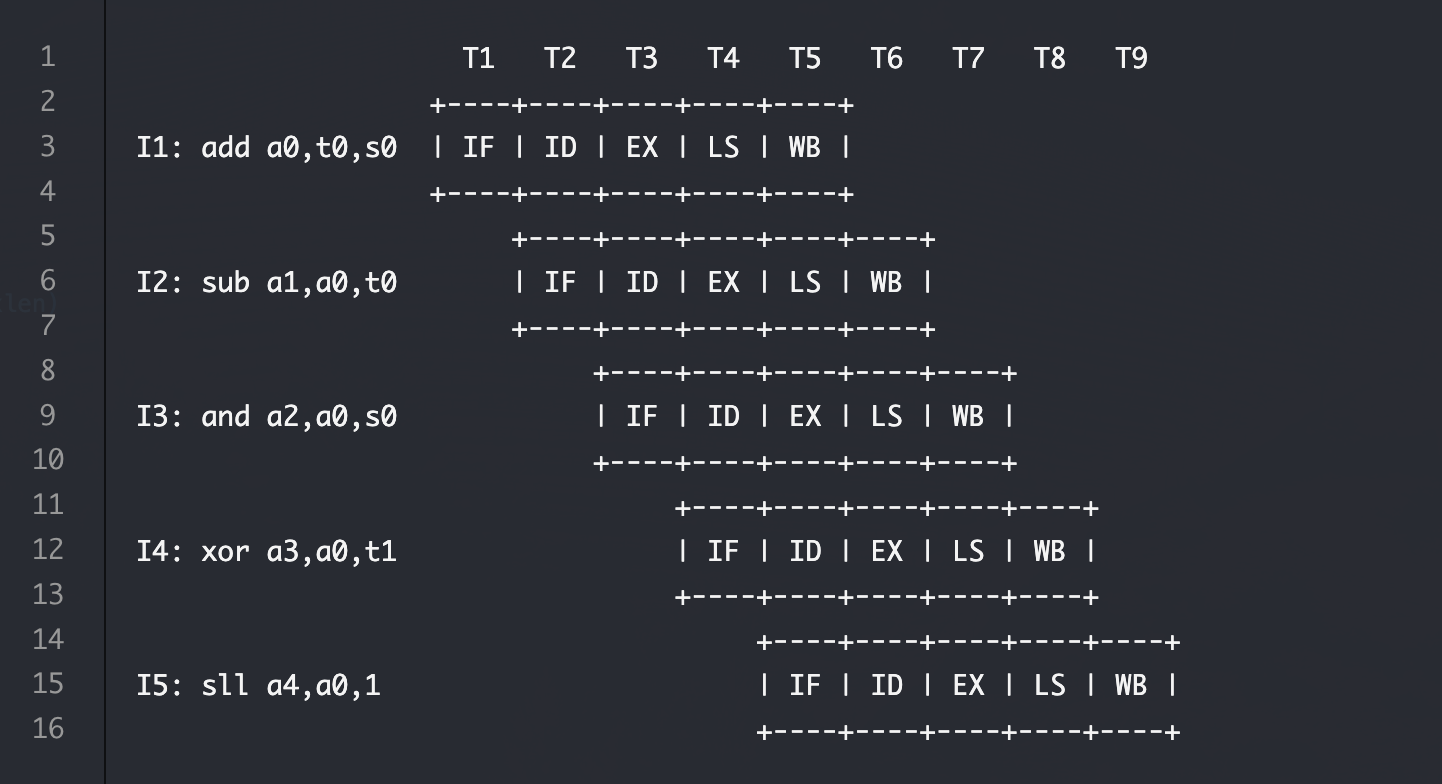
首先要理解数据冒险,哎,其实想象一下,指令正一条一条的通过流水线,每一个部件都在全力工作,每一个部件都在处理不同的指令,就在这时,某一条指令到了idu执行阶段,发现他需要读出x1寄存器,但是,另一条older指令正在进行他的ex阶段,并且发现这一条指令需要对x1寄存器进行写入,此时,那一条执行到idu的指令就需要将总线暂停,直到那一条在exu的冲突指令完成他的wb阶段
上面这段伪代码是讲义中的,其实idu和后面一条指令存在冲突在最早exu中就会被检测出来,但是需要等待这一条指令和那些也在流水线的指令全部通过,后面几个stage完全没有冲突的时候,才能说没有冲突,还有可能是某条指令执行到idu时与一条正在lsu的指令存在冲突,此时也应该阻塞,总之,这就是我的一点理解
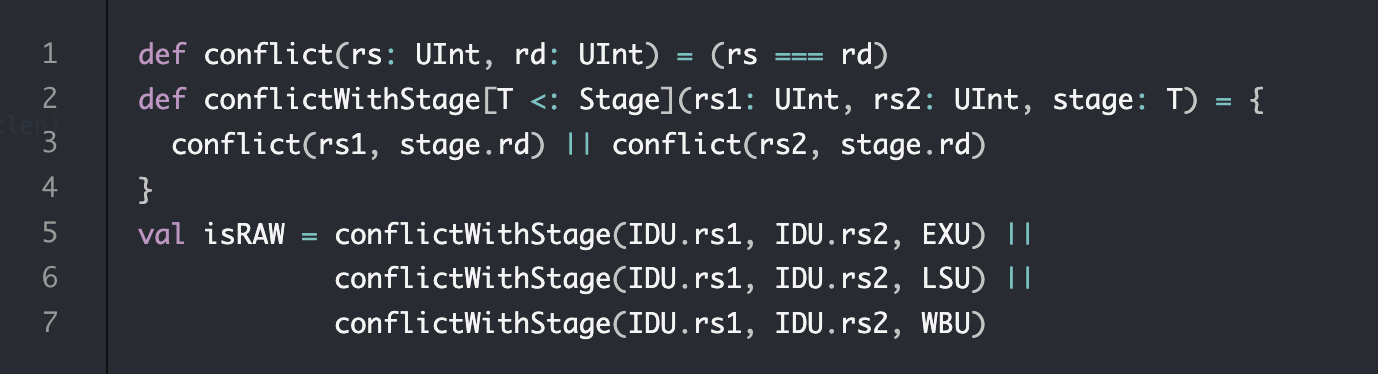
检测到raw,直接最简单的将idu的io.in.ready=0 io.out.valid=0即可,甚至都不需要增加什么状态机之类的

讲义太贴心了,这两波直接让这个任务简单了n倍
是否写入寄存器取决于某一个enable信号,可以复用,是否正在执行指令取决于此模块的io.in.ready(如果为1说明此模块空闲,为0要不说明此模块正在工作,要不说明此模块被某些事情阻塞了,总之也是正在忙,数据肯定是valid的,但是忽然发现有问题,有的可以一个周期结束的模块ready可以恒为1,需要再想一个办法获得这个模块的流水线寄存器中是否保存了有效数据,梳理一下,in.valid之后流水线寄存器保存有效数据,out.valid之后,模块根据有效数据进行处理结束,流水线寄存器保存的数据无效,其实还有一种方式,就是in.valid | ~in.ready,就可以排除那些一周期结束的模块,只要这个条件满足,就说明这个模块在忙,我感觉这个方式对于我的面积更友好一点),至于并非每个指令都需要读出rs2,说实在的我不知道有什么很简单的方式实现,唯一想到的方式就是每一个指令比对一下,即在译码阶段多加两个译码信号,标识rs1和rs2是否有效,也就是ren信号
我发现写完有点难以测试,只能肉眼debug,我决定还是修一下difftest,修difftest的时候发现一个问题,我的pcReg更新时机感觉不太对,似乎不是和其他寄存器一起更新的,我感觉这有一点不符合isa规范,但是我现在不知道怎么解决,而且感觉暂时问题不大,我就先不比pc好了
中间遇到了一个soc的问题,给araddr但是rvalid为1时返回的rdata是0,但是我的mtrace却显示读出的rdata不为0,快速波形定位到axi4delayer的错误
最终面积:29915.424000,频率:499,尝试变成4,1,16 icache,面积33489.134000,频率不变
解决控制冒险
我之前根本就不算是一个真正的流水线,我是上一个exu执行完,计算出下一个pc我才更新pc,根本就不存在控制冒险,而现在我需要ifu每个周期都取出一条指令,然后在exu计算出真正的pc时,通过和数据冒险相似的检测方式检测各个流水线部件的pc值,然后做流水线清空操作
感觉还是有点难的,包括推测,检测,恢复,每一个都有比较多的细节要处理
让我先用自然语言来描述各个阶段需要处理的细节
推测执行
需让pfu持续的选择推测的pc,然后将out.valid置1即可,由于之前是等当前指令执行到exu再计算出pc,所以ifu不会存在ready为0,pfu valid为1的情况,但是现在每一个周期pfu都要计算出一条新的pc,所以pfu还需要实现一个状态机,实现等待ifu的功能
接下来就要考虑一下pfu的几个状态,pfu有来自几个模块的输入,ifu给他的ready,idu给他的某些pc值,exu给他的某些pc值和pc选择信号,基本上来说,需要跳的指令最早会在idu判断出来,但是
嘶…..不清楚哎,但是这说明了所有跳转指令都最好在exu阶段确定需要跳转的pc值,所以可以将idu的几个信号往前面流水线放一下,可惜这就会导致多出64个DFF的面积,哎,没办法,这64个没法优化
所以现在输入是当前的1,pcReg的值 2,ifu的ready 3,exu的valid和bits,输出是valid和nextpc
至少两个状态,waitifu,waitexu,但是这会导致将pfu当成一个新的流水级,这并不是我希望的
我觉得在写代码之前我需要画好框图
有点悟了,我的ifu和pfu之前没有一个流水线寄存器,五级流水线应该是每一个模块前面都要有一个流水线寄存器的
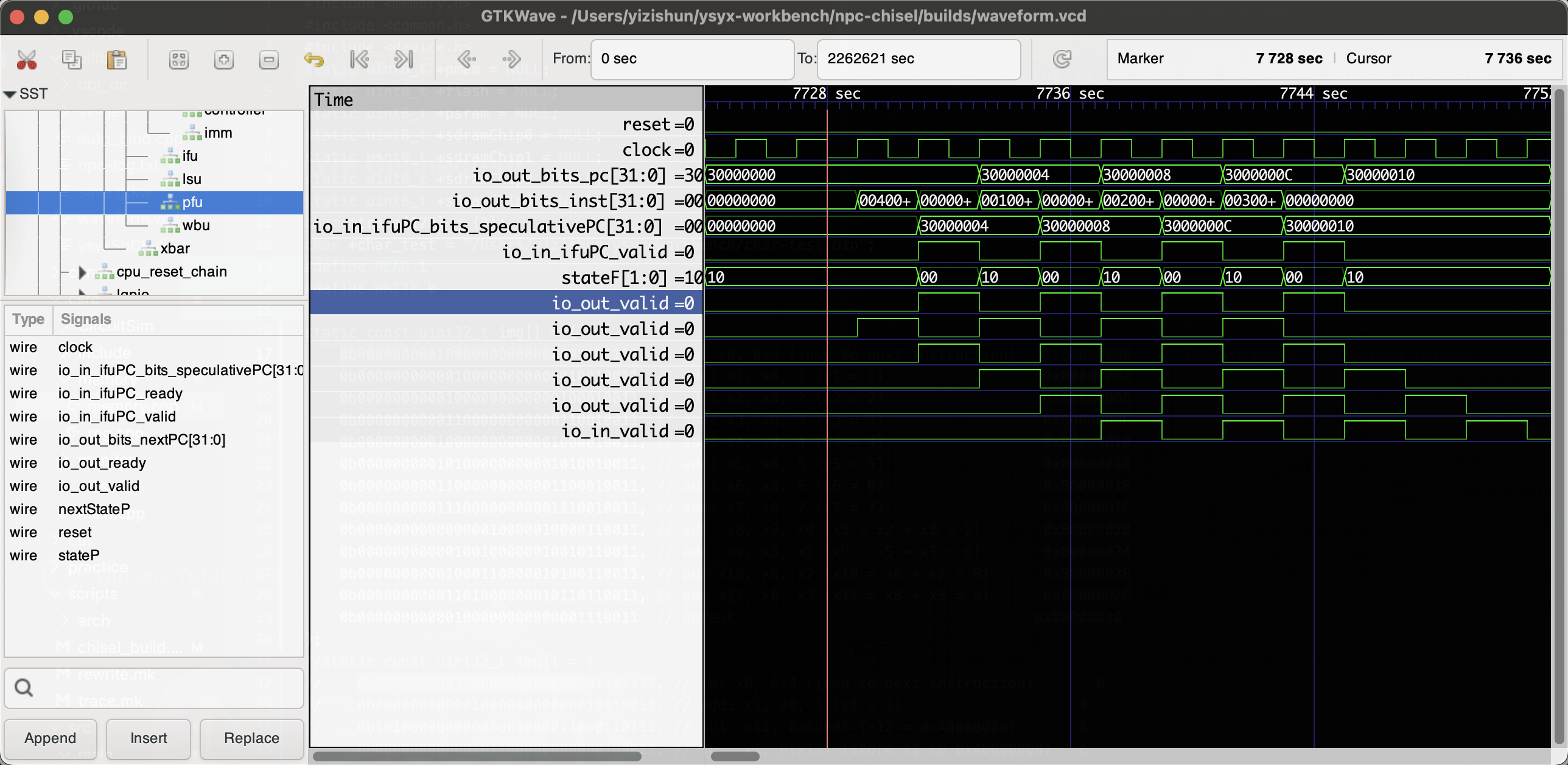
看这波形感觉问题不大啊,之所以每一条指令都是两个周期,主要是icache和ifu之间插了一个寄存器(否则关键路径有点大),来一个对比
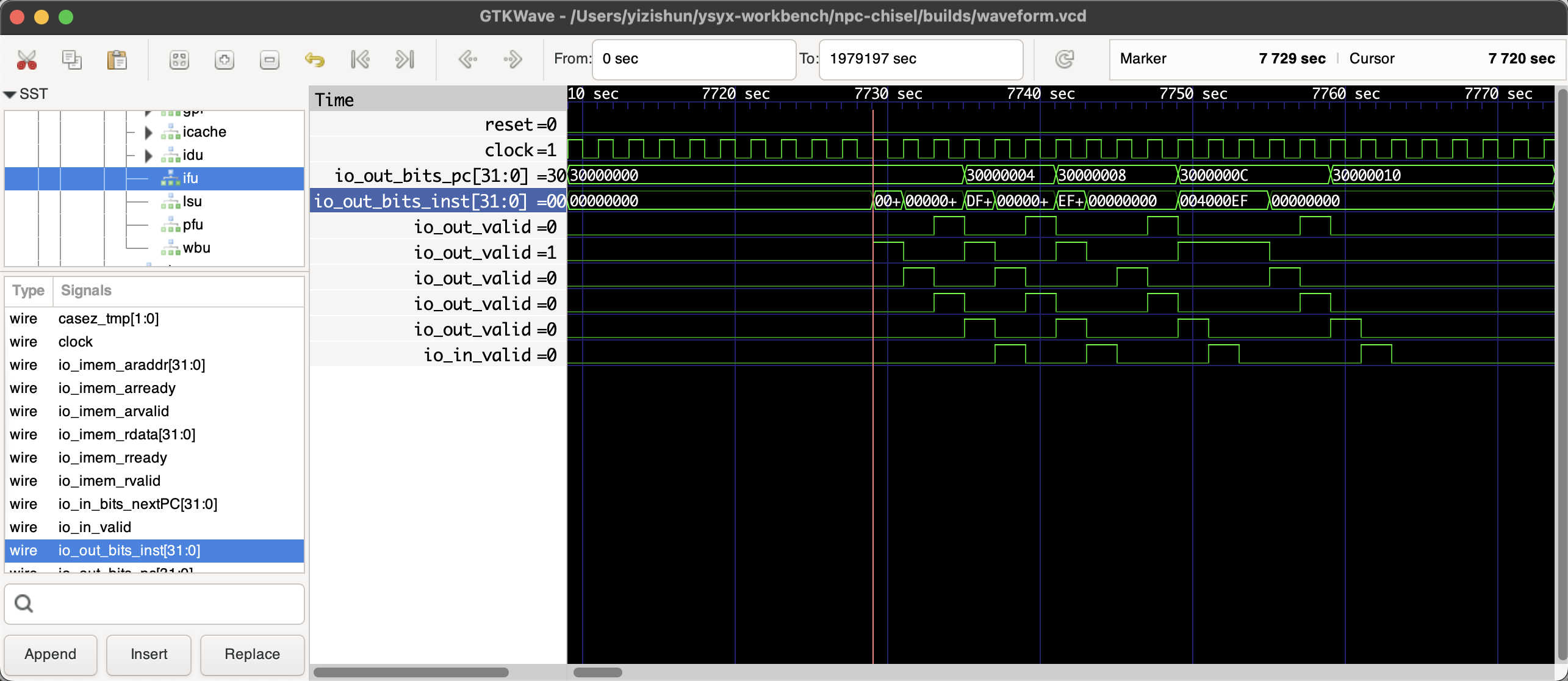
因为在有一个pfu的流水线寄存器,我预测频率可以到700往上,但是真实却只有509,我一看,关键路径变成clint了…..
一气之下重写了一下clint(之前还是用verilog写的,我也不知道为啥用verilog写)
但是我发现时序并没有变好,这种模块访问的频率其实不高,我可以使用寄存器进行切分,修改方式很简单,仅需将mealy改成moore即可,但是发现还是不太行,因为我的io.rdata始终是在当前周期计算的,所以需要加一个寄存器,加了一个寄存器不知道为啥面积直接加了近300,但是频率却如愿到达了626,关键路径还是exu,alu占了一大半,关键路径甚至不会经过idupc,那这样我就可以让ifu在一个周期内取到指令,letme try
下面请欣赏没有冒险的,IPC为1的一个五级流水
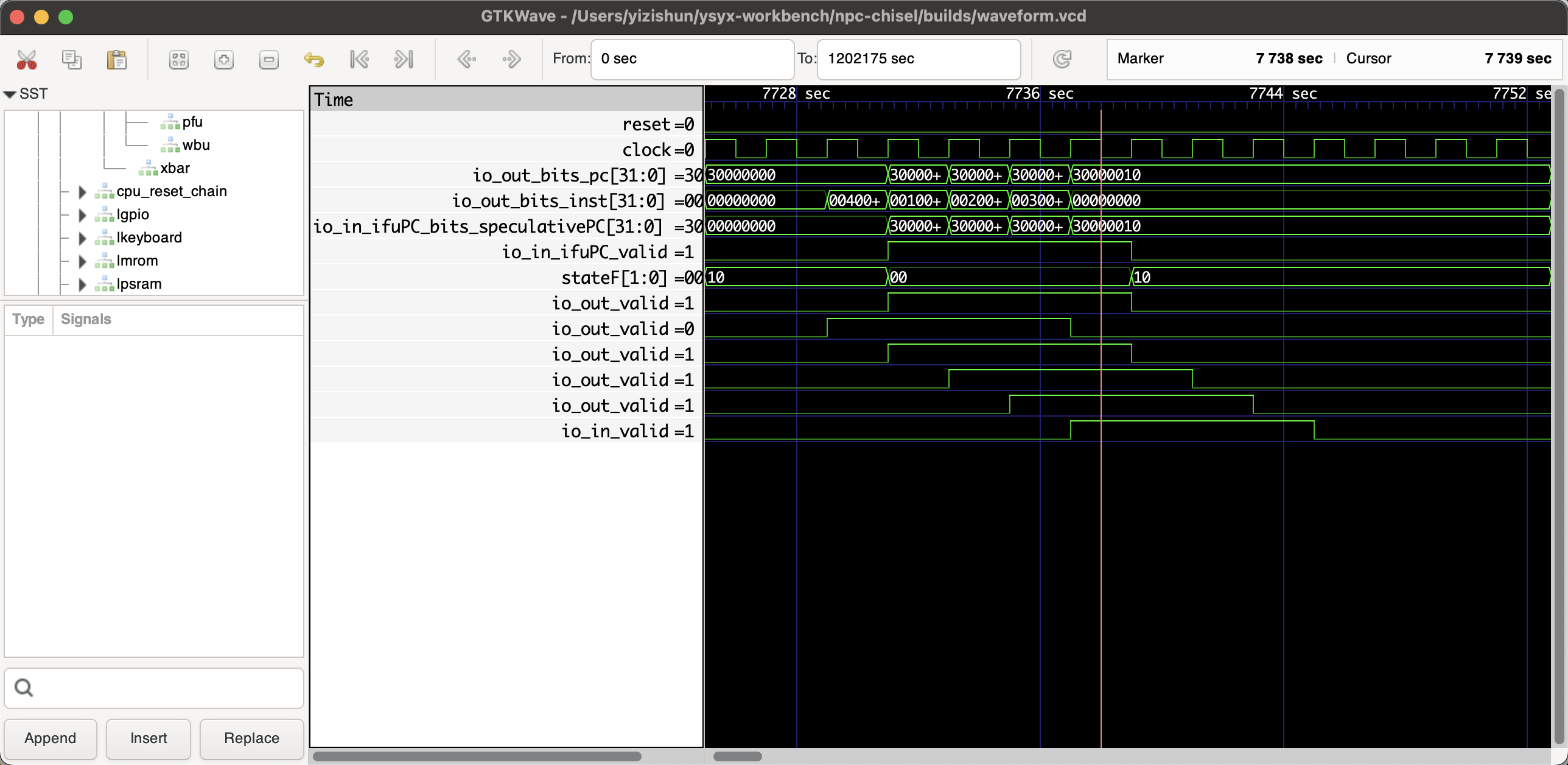
在icache为4,1,16下,面积为32321.394000,频率为626.772
检查机制
在不考虑异常的情况下,某些指令在exu阶段才可以确定下一条指令的地址,这意味着我们只需要采样exu的某些信号与前几个模块做对比就可以发现是否存在控制冒险。
首先,确保这条指令是跳转指令,我正好有一个jump控制信号来判断
然后,我个人暂时感觉,假如当前指令到达了exu,那预测的下一条指令应该到达了上一个正在工作的模块,比如,如果exu有某一条指令到达了exu,就先找出上一个正在工作的模块,比如,idu正在工作,或者说ifu还在取这一条指令,此时就是ifu,然后就检测这个模块的pc和exu计算出来的是不是相同,如果不同,说明检测出来了冒险冲突
反正在实现时遇到了一个问题

reset信号不同
冲刷
我给每一个模块都给了一个冲刷信号,基本就是将所有信号恢复至初始,将能一个周期回来的状态回来,不能就再加状态机回来,如果已经状态已经是初始,就不需要再回来了
在跑dummy.c的时候出现至少两位数的bug,等我都解决之后我需要粗略总结一下
等我能跑过dummy之后,尝试跑水仙花,但是difftest检测到了一个神奇的错误,ref好像比dut快一条指令的感觉,好奇怪,我暂时难以定位到具体的错误,但是我正好要去旅游了,没法debug了,所以记录一下,不过我认为我旅游回来的第一件是是整理我这些debug之后的所有更改,对流水线模块之间的交互有更深刻的认识,再回来de这个bug
我看了一下设计实战里面的模块间握手信号,突然有种将自己的代码全部推到重来的冲动
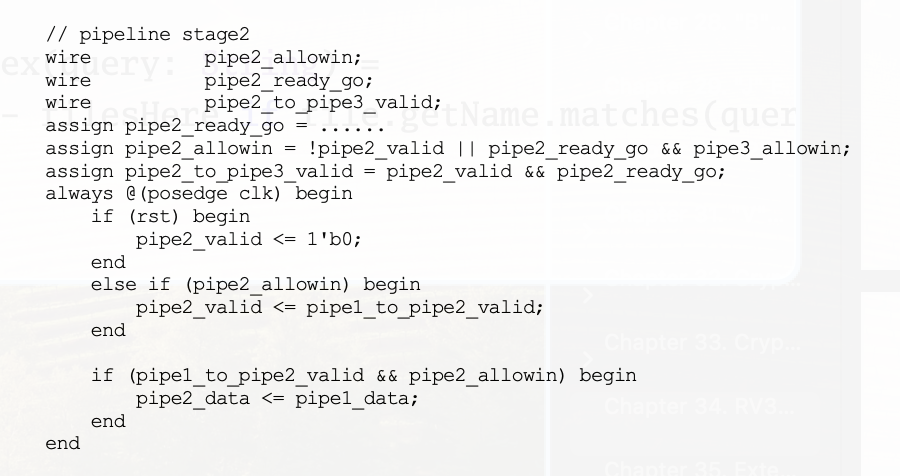
不过我第一件事应该是了解我和他的区别,我的存在一个状态转移,但是我觉得我的状态转移有一点点没用,但是更加比上述的更加直观,状态机最大的作用是保存当前的状态,记录一些顺序,记录一些输入给不了的信息,比如当当前模块数据ready go,但是下游模块没有allow in,状态机就可以记录当前状态,然后保持valid不变,我打算先将那些一个周期可以完成全部计算的模块取消掉状态机,比如idu和exu,wbu
我觉得上述cpu设计实战的代码最好的一点就是节藕,仅仅让ready_go信号与本模块相关,特别是那些一个周期就可以完成计算的模块,比如exu,ready_go可以一直置1,但是对于多个模块才能完成的,比如ifu,lsu,lsu需要等待axi通道的握手,比如需要10个周期,那前9个周期readygo就是0,这种多周期的必须需要状态机,最重要的两个分别是什么时候开始第一个周期,和什么时候结束最后一个周期,我觉得是上一个周期in.ready,本周期in.valid,这种情况就要开始这个多周期模块的第一个周期,当完成到最后一个周期后,需要将readygo置1,直到out.ready为1,这时候需要等待下一个周期再结束最后一个周期,也就是将readygo置0,其实这种没有做到完全的节藕,但是使得readygo仅与当前模块有关,还是做到了一定程度上的节藕的
这似乎是一种抽象思想,模块其实仅仅需要处理readygo信号而不是复杂的握手信号,但是这仅限于单周期就可以完成的模块,如果一个模块需要多个周期才能完成,按照上面的分析,我觉得我需要给模块在readygo这种层次上更多的抽象信号,第一个是start信号,指示着这个多周期模块需要开始进行工作,第二个是end信号,指示着这个模块可以重新回到最初状态,start信号为1时,模块可以立马进行工作,但是end信号为1时,模块需要下一个周期才能回到最初状态,这就是这两个信号的规范,这样,这个模块就被抽象为一个机器,start开始工作,end可以结束工作,readygo指示模块内部的状态,而在最开始处理握手信号,使得模块本身无需考虑任何握手信号
按照上述重构之后,跑通了cputest,但是,时序爆炸了,只有200多mhz了,看关键路径,是exu->idupc->core(检测控制冒险)->ifu->icache->xbar->icache->ifu->idu流水间寄存器,无敌长关键路径,大概需要对半切一下?
在优化时序之前,我想先优化一下面积,我可以多给gpr几个读口,然后流水线传递时只传递寄存器编号,但是发现需要增加至少两个gpr的读口,实验一下会使gpr的面积增加2000,似乎得不偿失,其他我还没有什么优化的想法
在上述组合逻辑中添加了两个寄存器切分,并减少icache面积,最终面积30196.320000,频率532.110
实现异常处理

感觉基本的思路就是在每一条指令的信息中插入一个stat状态信息,标识着这条指令的状态(正常?异常?),然后整个处理器有一个stat寄存器,标识着整个处理器核的状态,每一条指令到达wbu时将自己指令的stat写入处理器的stat状态,然后每一个模块还会读这个寄存器(的变化,即写使能为1,且要写入的值为异常,从而保证这个异常信号只存在一个周期,只会冲刷一个周期),如果stat寄存器为异常,首先冲刷所有模块,然后从ifu开始说:ifu接收到正确的pc(mtvec),ifu下一个周期获得这个pc,然后开始取指令,与此同时,csr模块将mepc写入(所以某个模块出现异常,需要修改当前指令csr相关的控制信号,从而传入wbu时可以写入正确的mepc),写入mcause(即stat寄存器内容),然后开始异常处理指令流
上述机制至少可以保证:1,正确处理多个异常。2,在推测错误的指令出现异常时能正确恢复(因为他根本到不了wb阶段)
我发现上述异常处理其实可以更简单,只需要让每一个模块实现冲刷机制(ifu,idu,exu已经实现了),然后将ifu的pc输入变为mtvec,然后唯一一个需要特殊对待的模块是csr模块,他需要内部写入mepc和mcause
最后成功跑通rtt
之后有一个形式化验证的任务,不是必做题,而且感觉好难🤯,验证这个方面感觉好复杂(主要是觉得很陌生),打算先跳过了,主要是我不懂,那些axi信号也是core的输入,然后axi信号有很复杂的依赖关系,他这种随机输入的值不满足这些关系怎么办捏,感觉还是不理解这种smt到底是个啥,记得之前jyy还发过一个视频,应该是去年看的,讲的就是z3是什么,https://www.bilibili.com/video/BV1d841167EW/?spm_id_from=333.999.0.0&vd_source=9d92636f938d2ae062a6b23f118d19d1,当时就觉得迷迷糊糊的,不过还是先跳过这个任务好了,之后可能龙芯杯需要他,那之后再说吧
形式化验证
TODO(不知道啥时候会回来填这个坑)
让流水线流起来
跑了两次microbench都莫名其妙寄了
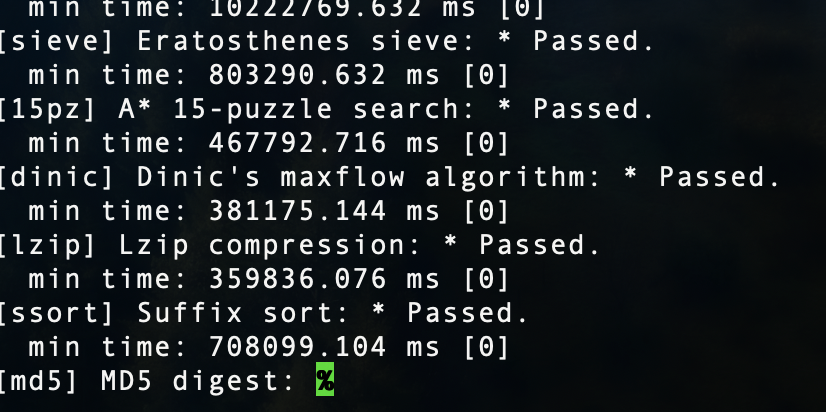
都是寄在这个md5上面,我:?????
每次跑一个小时多,每次都寄在这里,第一次我是开着difftest跑的,寄在这里了,我以为是操作系统把这个进程kill了,然后我关了difftest跑,还是寄了,我就知道不是difftest的缘故,但是为啥会寄呢?也没有触发什么assert啊,就算是卡在了某个访存,也不应该莫名其妙的没啊,让我看看microbench的代码,试试能不能让他只跑md5试试,看是不是md5这个程序的问题,我发现md5还是最后一个,呜呜呜,每次到最后一个寄了,我哭
我把md5顺序调换到第一个,试试跑md5,但很快我就发现不是他的锅

这就有点棘手了,无法定位到bug是最恶心的bug,最主要的就是这种bug需要超长时间才能定位,既然是超长时间,我试一下test模式能不能复现这个问题,没法复现,这可怎么办?
实在没办法了,我因为卡在这里(跑一次需要最短1h25min,最长要4h多,而且中途都没办法做其他事情,会很卡)已经一整个白天了,于是我在群里问了一下,马上就有万能的群友解决了我的问题,是cpu_exec函数的n开的太小了,导致执行到后面n直接为0了,直接结束执行了

我首先就增加了两个计数器,分别是ifu和lsu取到值但是是个废值的情况,然后exu阻塞时也会被记录时间,就算是计算效率吧,没办法其实,ifu和lsu的最大吞吐量都是1,但是需要hit以及不是访存指令时才是1,其他情况由于频率变高,我又校准了一遍访存延迟,现在访存需要更多的周期阻塞了,吞吐量最差时还是要十几个周期
后面就是三种优化,分别是对icache的优化,减少流水线数据冒险的阻塞,减少控制冒险的情况
我的icache是一个周期返回数据,然后关键路径也不再icache中,so,我不需要做第一个优化,但是第一个优化想法真挺不错的,把基本不存在冒险的多个阶段流水化以在提升主频的基础上保持ipc不变
转发

感觉还挺简单的,面积加了1300,频率不变
感觉最主要的就是检测到转发的数据然后替代idu的输出,这样逻辑可能会少一下
但是这个面积增的有点多,难受
忽然发现我跑microbench的时候出错了,定位了一下,发现是当某条指令同时需要rs1和rs2,并且rs1和rs2都依赖于前面的指令,rs1可以立即转发,而rs2需要之后的周期才能转发时,没有正确的stall idu(而且这波指令序列是两个lw后面紧跟着需要读出两个lw的寄存器的一个指令,所以导致第一个可以转发时,第二个可能还没开始做访存)
还是想得太简单了,我一直都是考虑的单个转发,如果是多个转发恐怕需要再加寄存器,让我本不富裕的面积雪上加霜
而且想了一下好像没啥思路?我忽然想写状态机了,waitrs1,waitrs2,但是是不是没有必要?不过也没有别的想法了诶,不对,应该不需要复杂的状态机,我只需要一个count就行了,当idu.io.in.valid=1时,通过判断rs1ren以及rs1israw和对应的rs2来选择增加这个count,然后每获得一个转发数据就减一,直到减到0,count不为0就stalling,perfect
忽然发现还存在一个问题,就是某条指令为lw a3,592(a3),很搞
分支预测

一次预测错误导致2条指令白取了,而且在跳转指令时必错,开销挺大的,数据转发没有达到我心里预想的效果,因为每次最多也就快个几个周期,但是控制冒险的恢复很多是会导致指令重取的,每次会导致有几十个周期的浪费,而且跳转指令还挺多的

还是打算通过这个锻炼我的c++水平,使用一个abs类将某个predict函数设置为纯虚,然后各种不同的策略继承他并提供实现
先简单的实现了一下always take和not take和BTFN,发现他们竟然差距这么大
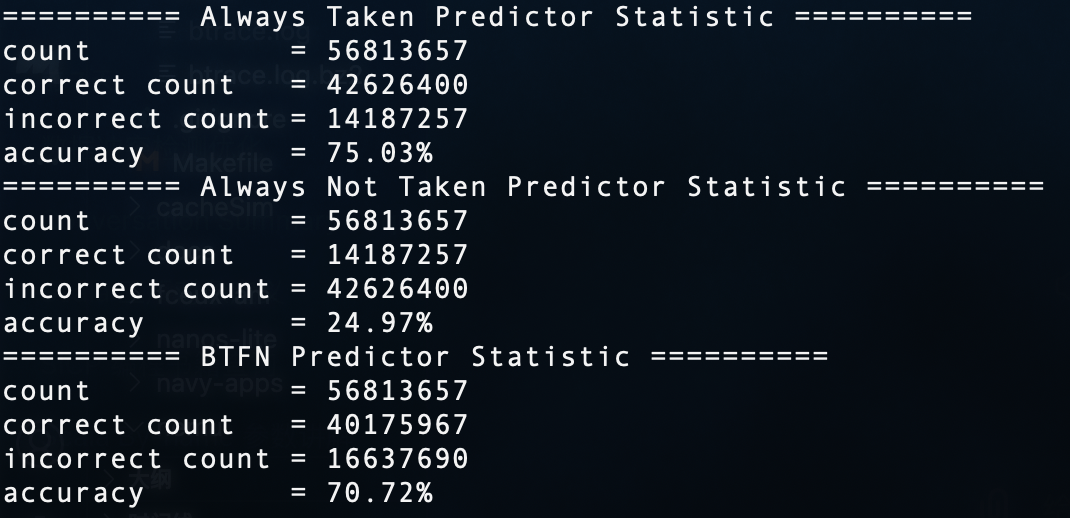
不过这个BTFN为啥比always taken还差,有点不理解哎
至于更高级的动态预测算法,由于npc的面积是不可能允许我实现的,所以我现在暂时不去学习,但是之后的龙芯杯肯定要去学习的,因为面积不再是限制因素,到时候可能需要稍微改动一下我的bransim的译码部分
我试试面积能不能允许我实现一个always taken的分支预测器

需要实现一个BTB,其实我的第一想法是将ifu和idu合并来获得跳转目标再取指令,但是这会很影响ifu的取指效率(因为可能存在阻塞),BTB的话,有点占面积是真的😭
先在branchsim校准一下好了
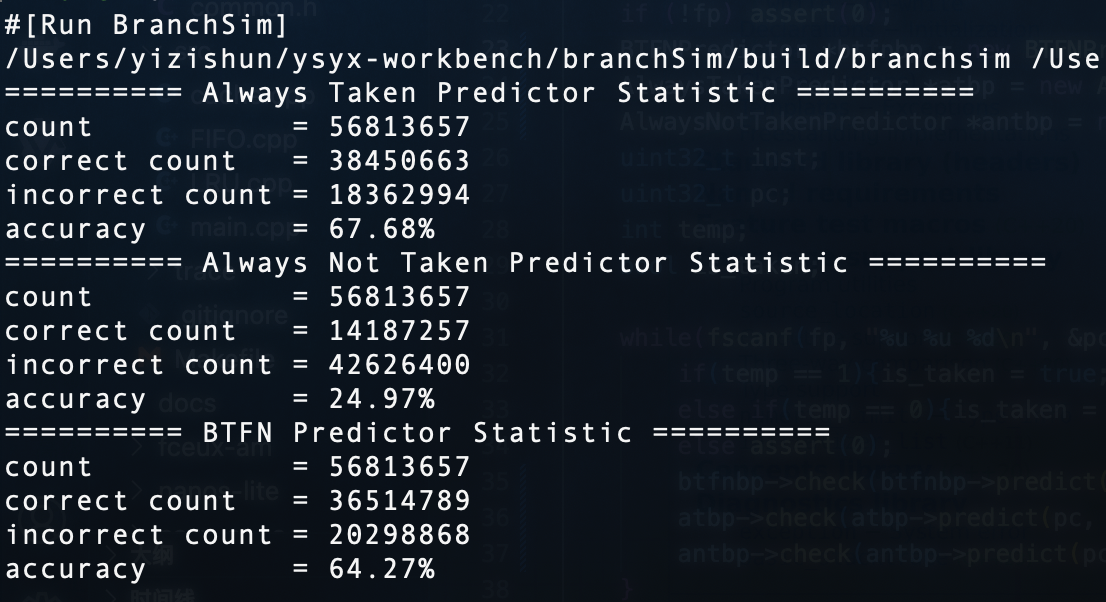
当btb的参数为直接映射+index=8+blockSize=4时,跑出的结果
将index修改为2(因为这个才是有一点可能的)
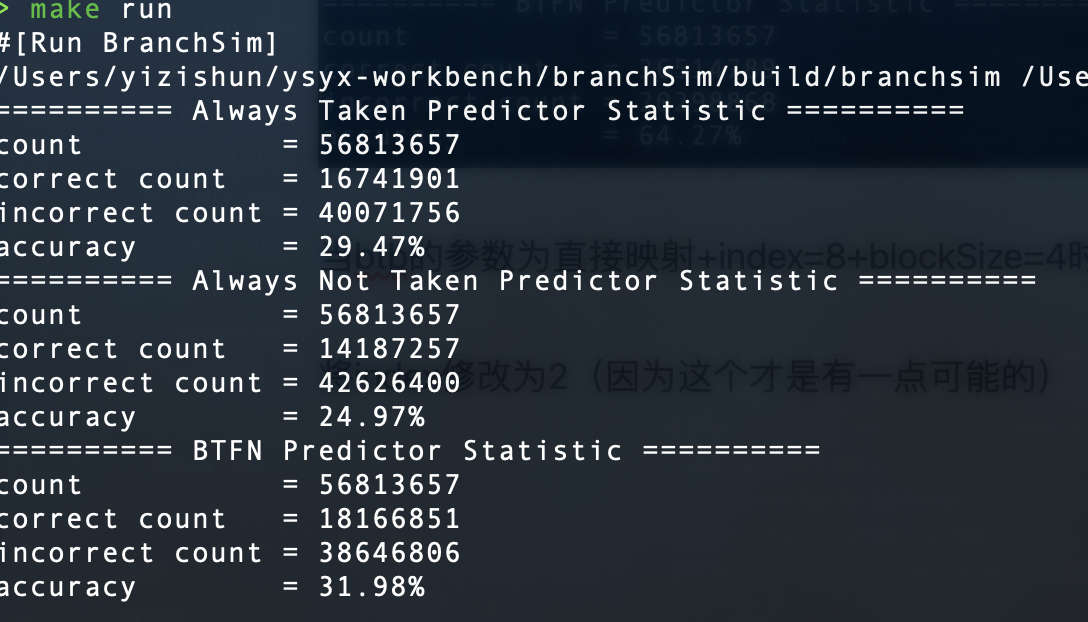
太拉了,感觉得要8才能有一点点效果
还是打算实现一个,然后参数化来实现拆卸(或者我还可以只存jal)
TODO(打算实现完fence.i再来实现这个)
fence.i
太简单了,十分钟的事,不过我是在idu做的fencei,就只要冲刷掉ifu即可,然后主要fencei可能会让icache产生多个写口,可能需要分时复用一下
面积时序优化
将所有chisel代码中的dontTouch删除,频率提升到517.043MHZ,但是面积增加了100,面积为33948.782000