
前言:本篇文章为笔者参加第六期一生一芯的日记,记录了每日debug经历,以及各种吐槽,水平有限请谨慎参考
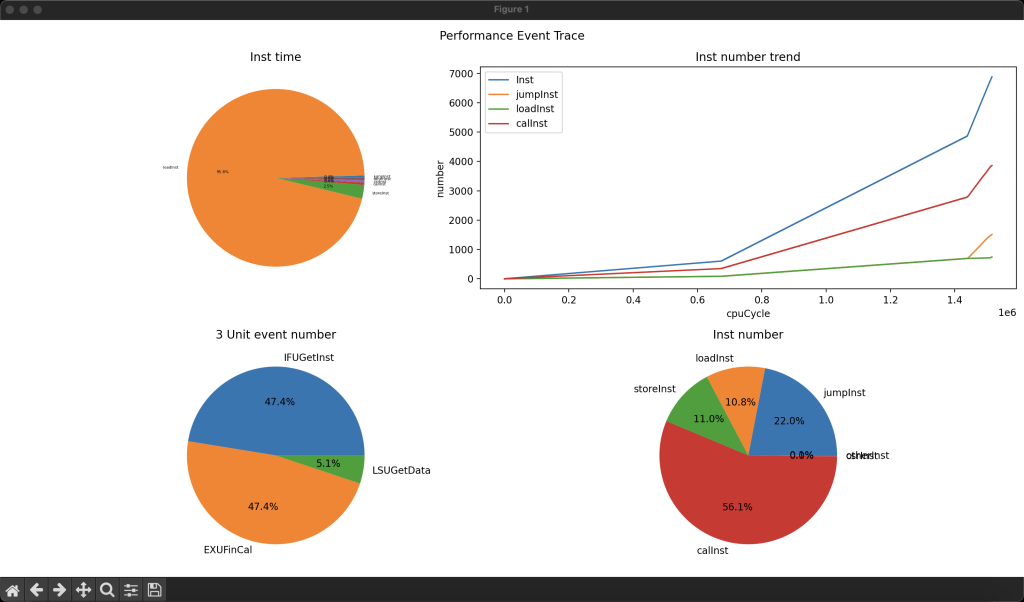
寻找性能瓶颈
IPC取决于微结构的设计,比如多周期的IPC肯定很低,毕竟一条指令要多个周期,所以一生一芯项目主要是要优化IPC(程序指令取决程序的写法和编译器,频率取决于时序优化,也不是一生一芯的重点)

……预期之内,这是跑dummy的原因,大多数时间都花在bootloader上面了,flash和写sdram的时间比较多
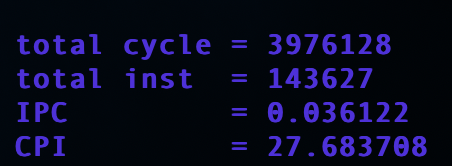
水仙花,三倍的提升,其实我还开了lsfr

这个任务我打算还是使用dpi-c实现,毕竟c环境能使用的奇技淫巧更多,我打算提供给RTL环境一个唯一的接口,这个接口是所有其他事件的wrapper,通过识别具体的事件调用不同的函数,在不同的函数中进行判断是否增加对应性能寄存器的值,所以RTL环境至少提供给warpper三个参数,事件类型,能指示计数器增加的信号,事件类型的子类型(比如译码逻辑译码出的不同指令)可以将计数器实现为一个类,但是其私有数据只有一个,方法也不多,每一个类的方法还需要单独实现,所以没必要
这个第二个任务我一开始完全不能理解,ifu怎么还能取不到指令,后来觉得是ifu的时间花在了哪些上面,如果说第一个任务计数器是数量(宏观),那第二个其实就是第二个维度,时间,记录每一个事件一次的时间。记录时间就首先要知道每一个事件的开始事件和结束时间。
第一个任务的开始时间应该是exu开始的时刻(或者说取出指令的时刻),结束时间应该是wbu写回的时刻,我觉得应该就是处理器后端处理的时间
第二个任务是说ifu把时间都花在哪里了,分分类吧
- 等待握手的空闲时刻
- lfsr的延迟
- 访存延迟
- axi信号寄存器延迟

这是ifu的波形图,第一部分是lfsr的引入的随机延迟,然后等地址稳定后发出arvalid开始访存,当axi返回数据时状态变成11,然后经过一个寄存器的延迟发出给idu,我其实觉得没有什么好优化的,除了把这个随机延迟丢掉,但是这个随时可以丢掉无所谓
我现在只能想到这些,握手我好像用的状态机用的一直都是根据nextstate来指导output logic的,所以好像不存在握手的开销
第三个任务很简单,lsu的两次握手就是lsu的访存时间
后面发现store指令只需要20个周期,但是load指令需要100左右周期


性能瓶颈似乎很明显,在Load指令处,lsu花的时间太长了,难怪要加cache死命优化访存
我甚至将其做成了动态的,但是会很慢就是了
我的mac一直跑不起yosys,这次一定要综合成功一次
emmm,还是不行,我还是ssh连到外部ubuntu服务器跑综合吧
———分割线——————————————————-
中间经历了一次长时间的新疆旅游,旅游之后摆了一阵子,有很久时间没有碰ysyx了,需要一次代码review来恢复上下文,还好这一章我还没有做很多
首先来重新看一遍讲义或者是yzh老师的视频
我现在的任务应该是在校准访存延迟部分
但是在真正实现apb延迟模块之前,我需要知道在cpu中的一个周期等于在soc中外设的多少个周期,讲义中预设外设的工作频率是100MHZ(之前看的还是200来着,一看更新时间是最近更新的,看来ysyx的soc团队把外设频率降了一倍呜呜呜),我需要知道现在cpu的频率,所以我首先的工作是综合我的cpu,获取我的cpu频率
综合我的cpu
综合使用的工具是yosys,综合之后的时序分析工具是iEDA中的iSTA
因为一些原因,没法编译iEDA到我的macbook,于是打算ssh远程连接到我的服务器上面
综合之前需要将所有的dpi-c函数给去掉(感觉会很多,毕竟每一个soc的外设访存我都用的是dpi-c)
大多数都是访存的DPI-C,访存的存储器件,感觉这些颗粒最终还是要用其他的ip的,那我就简单的注释掉不知道可不可以(或者简单的实现为一个二维reg?)
草了,我是sb,我只是要综合我的处理器,我又不需要综合soc,太久没做了,全忘了
草了,远程服务器配置太低,综合的时候直接卡死了(具体来说不是在综合的时候,是在网表综合的时候)
跑了几遍,终于跑出来了,虽然综合出来了,可是看不懂,悲
认真的看了很久NPC.rpt文件,首先要明白一个概念,叫做nagative slack,就是你要求这个路径要1.9fs,但是这个路径却需要2.8,那他的nagative slack就是-0.9,WNS是指所有路径的所有nagative slack的最大值,TNS是所有路径的nagative之和。
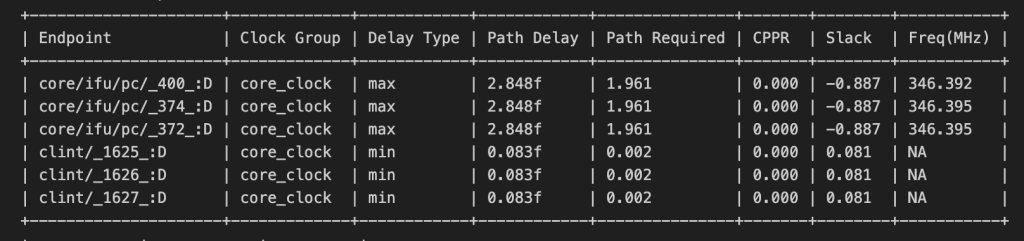
这个endpoint代表了一条路径的端点,并且代指的是endpoint为这个的一条路径
Path Delay和Path Required就是上面所说的真实延迟和所需延迟,slack就是nagative slack值,Freq就是在真实延迟下所能达到的延迟(之后使用350MHZ综合处理器,TNS直接变成-0.6了),前三个基本上就是整个路径的WNS
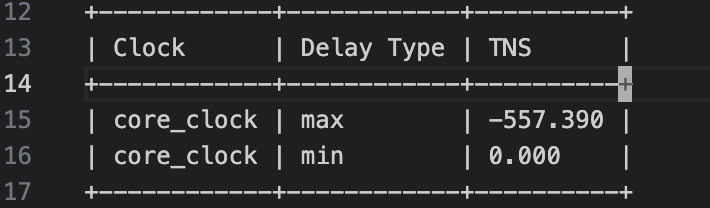
这就是所有的nagative slack之和,可以看到达到了-500之多
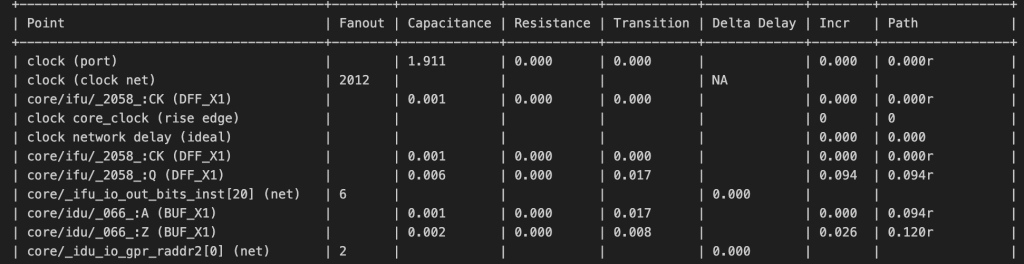
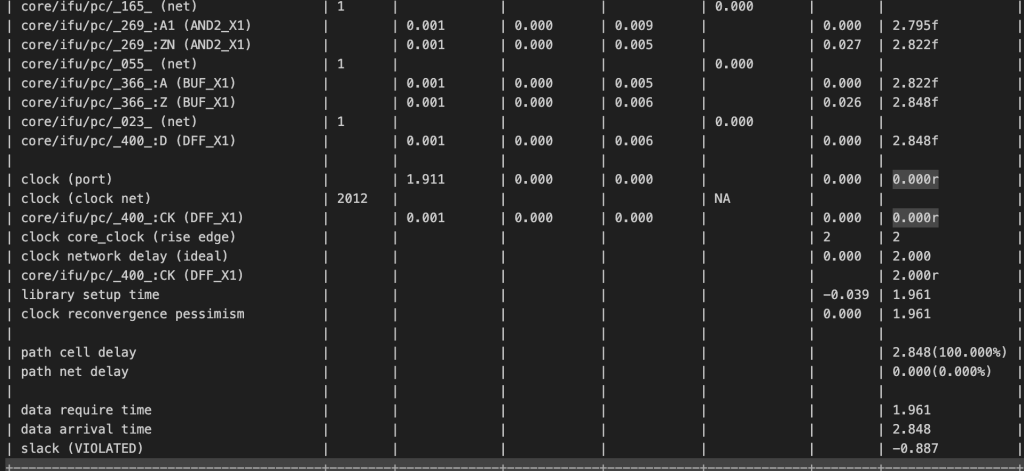
可以看到这是那个WNS的第一条路径,他将这个路径展开,详细到每一个point的延迟(主要是最后两列,incr就是这个point增加的延迟,Path就是累积到这个point的延迟),详细的看了一下,这个critical path主要是从ifu到idu(gpr)到exu再回到ifu的那一条路径,我觉得访存的路径肯定是最大的,但是由于没有将soc综合进来,所以这个并没有显示出来,所以还是不太准确的
校准访存延迟
350MHZ,那么r就是3.5,将s设定为2,其实等待的每周期只需要加2.5即可,因为npc也同时在等待中,假如t0是0,t1是4,那根据等式t1’就需要是14,在等待的每周期加2.5,累加器的值就是10,加上原本的4周期也正好是14,当然,真实的需要每周期加5减2即可
很明显的思路就是状态机,t0之前空闲状态,t0-t1等待设备状态,t1-t1’延迟状态
很久没写了,难写的地方应该在于对apb协议的实现,但是应该不会太难,毕竟apb就几个信号,手册还有完整的波形图

这个任务是寻找最大可能的工作频率
第一个寄存器,直接使用cpu的gpr,第二个就直接用alu得了
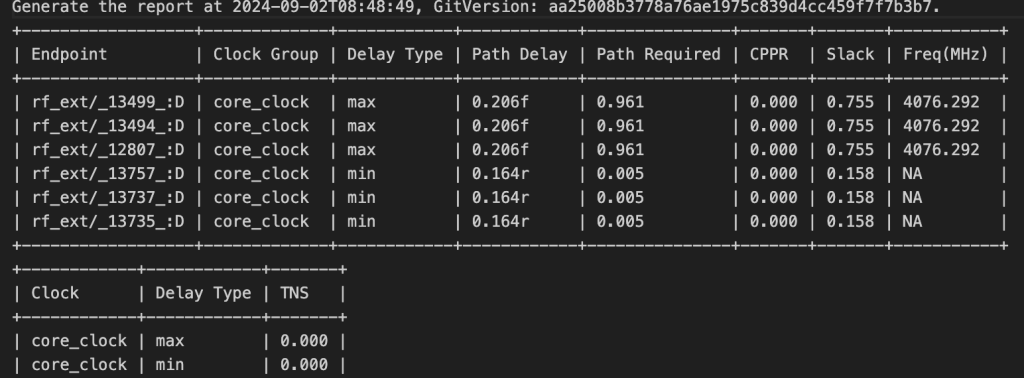
寄存器的延迟使得上限在4GHZ
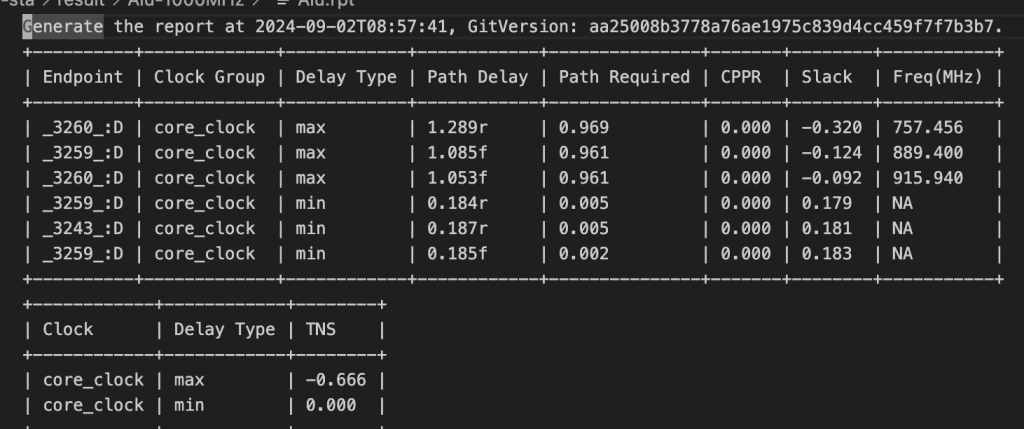
alu竟然频率这么低,让我仅仅试试加法
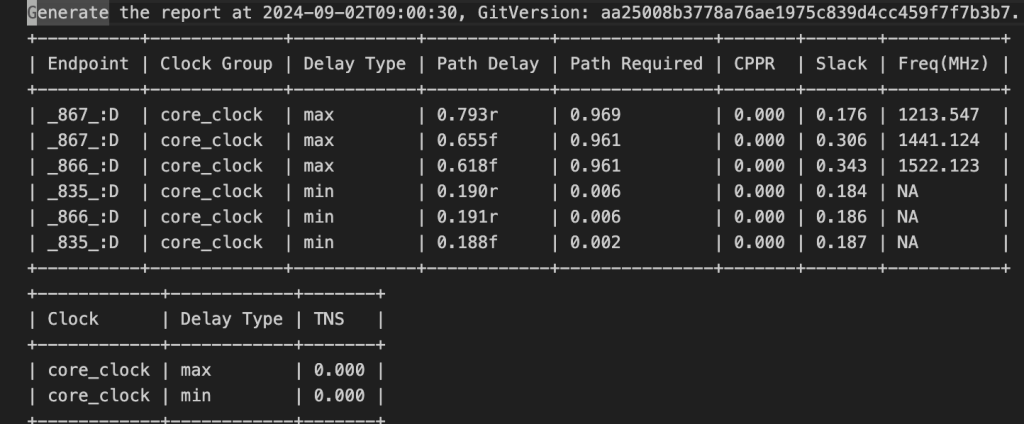
也只能跑1GHZ左右
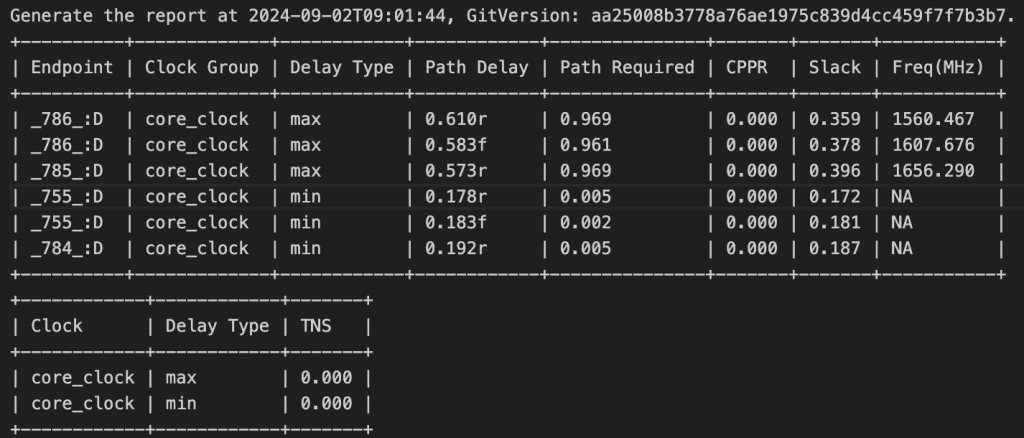
去掉zf的计算逻辑,1.5GHZ大概就是上限了,将32位改成16位,也大概在1.8GHZ左右了
我看别人的处理器,在这一步频率比我高,面积比我少,自闭了……
make perf我就实现成了make -C {microbench}然后执行测试,这个make perf我是在测试完之后的那次commit做的,但是似乎上一个commit就需要这个perf,所以又学到一招,git commit –amend -m{commit}可以融合这次改动到某一次commit,-m缺失默认上一次

不是~哥们~,怎么要整回去啊,我之前的感觉都删掉了…..
希望能实现一个丝滑切换的效果
两者的不同之处在于首先是am文件的不同,其次就是底层npc的实现,npc不需要包含soc的.v文件,但是需要包含自己实现的设备的文件(感觉要改好多地方,所以说我的代码可扩展性太差了,不过我也没有想到还需要转回来…..,正好把我的npc的makefile重构一波)
改chisel部分的话就是将之前的xbar拿过来,在顶层模块选择性例化哪个xbar就行
记录一下:之后需要切换,需要修改
1,makefile的ARCH变量,可以在命令行赋值(会控制src的选择和c仿真环境的改变)
2,chisel中的config.scala,(控制xbar的选择)(如果可以通过编译器工具传变量就好了,我就不需要改两个了呜呜呜)
3,clint中的addr(由于clint是verilog写的,然后clint地址又会在soc中用,所以需要修改)
感觉写的好烂啊,一点都没有达到丝滑切换的效果
在没有soc上面,串口输出好像有点问题
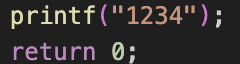

我觉得这是一个诡异的问题(连续putch就没问题,但是我的printf不应该有问题的),不过看起来真的像printf的问题,草,这问题太诡异了
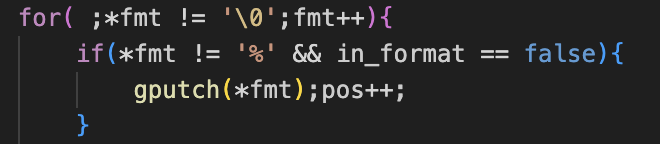
这一行代码很奇怪,明明每次都是fmt递增1,但是偏偏不输出24,我加了一行

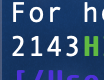
我很迷啊,这debug跟大海捞针有什么区别,通过一点嗅觉,我猜很有可能是我LSU在到soc中的行为与无soc的行为发生改变,但是我的sram没有因此而做出改变,ok我觉得有99%的可能是这个原因,奇怪的嗅觉天赋
写一下明天要做的任务:修改sram和uart的行为,使得与core契合(读:首先从中读出值,再适当左移或者重复数据来达到对齐要求,写:首先对齐地址,然后常规写入)
改了,输出正常了,但是跑microbench触发了assert,草了
尝试为其编写memtest来测试内存,果不其然,BAD TRAP
这个memtest的检测真好,定位bug的速度很快,很快发现是一个写的移位没移位成功,是因为一个信号位宽太短了
iCache
终于要做cache了,好兴奋!
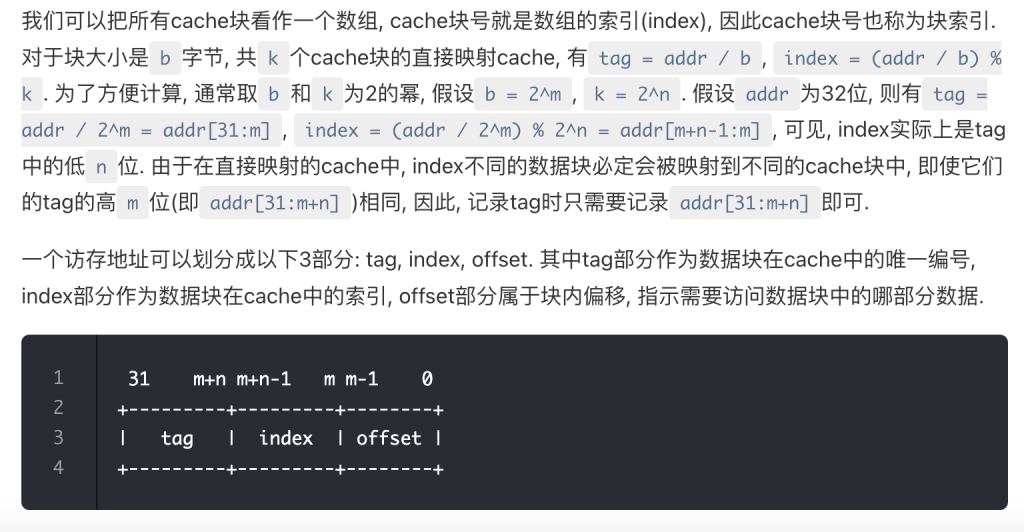
这一部分理解了一段时间,记录一下我的理解
首先这实际上是对dram中的内存做了两个分组操作,首先,按b字节为一组,分为了2^(31-m)个组,每一个组的标号是tag,也就是地址的高[31:m]位,低位为tag中每一个字节的索引,之后,对于这个大tag又进行了一次分组(这个分组的原因是cache大小小于dram的大小),这个时候地址的高[31:m+n]为一个组的索引,图中的index则是另一种意义上的offset(cache块offset),低位是字节offset
综上所述,对于dram主存中的大数组做了两次分组,大组的索引是tag,一个tag组可以完完全全正好放入一个cache中,然后index就指示了在这个tag组中cache块的索引,一个index组正好放入一个cache块,offset从字节层面指示在cache块中的索引(脑中需要有一个dram被分了两次组的图像)
至于最后一句“ index不同的数据块必定会被映射到不同的cache块中”,还可以这么说,一个cache块的index永远是相同的,是tag标识着这个cache块真正存放的是dram哪一部分的数据,而这不同部分块的数据之间的距离就是一个tag组的大小,即2^(m+n-1)

valid和tag来指示这个cache块中的数据存在于dram的哪一部分和是否有效(记住,index是隐含信息,确定了一个cache块就确定了一个index)


首先第一步应该确定icache应该放在哪个位置,core->arbiter->xbar->soc总线->dram,这是我的cpu一次访存的基本路径,访存信号经过xbar的时候先判断是否是clint,不是就是进入soc总线,如果放在soc和xbar之间,恐怕有写设备的访问也会进入icache,但是根据第二个黄框,只有flash,sdram的访问时候icache,其实本质的问题就是soc的访问是由哪一个模块来做,这很像一个arbiter的感觉呀(多个master,一个是icache,一个是xbar对于uart等设备的访问)
与其添加新的arb,不如复用之前的arb
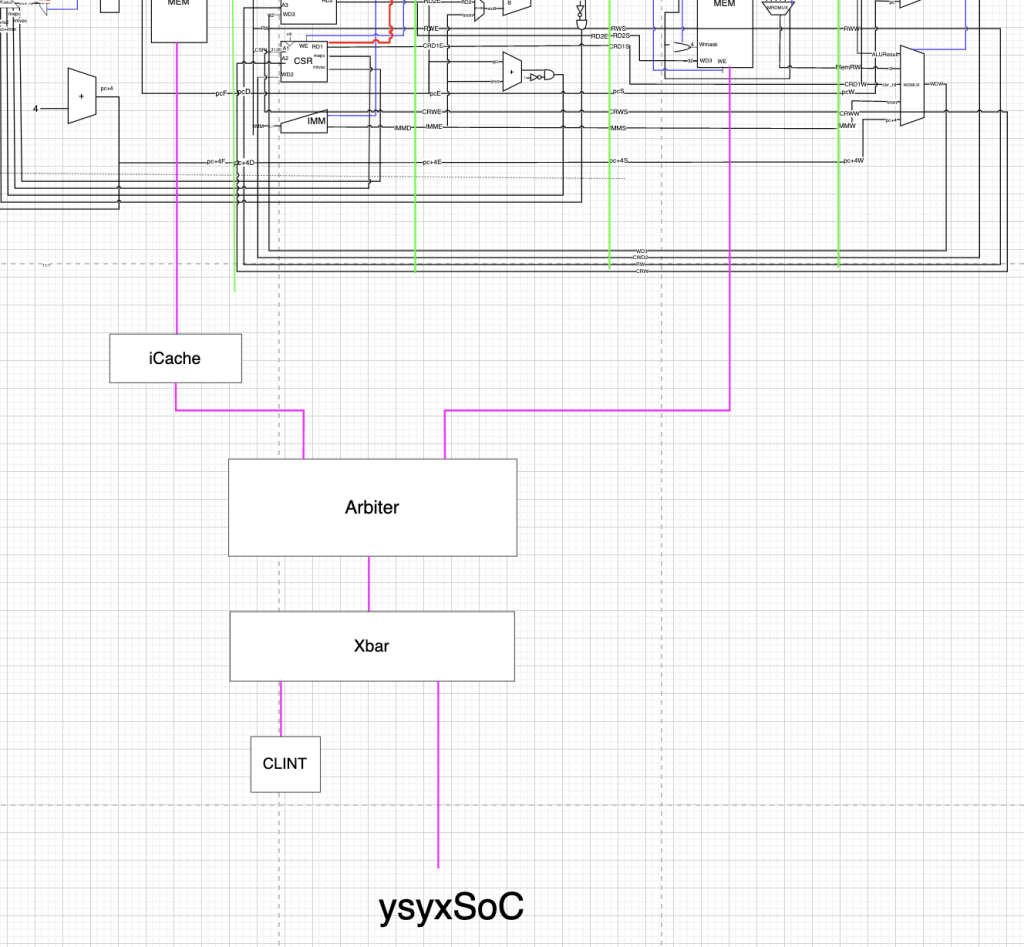
上面没显示完全的是处理器结构,紫色的线全部都是AXI4协议
icache需要对总线进行访问(根据块大小的不同可能需要多次访问(瞥了一眼后面的讲义,要用到axi的突发传输,我估计就是来实现这个多次访问的),希望可以做成可配置的)
是一个总线状态机,需要接管axi协议,感觉很简单…,有一些小bug,都只是因为脑抽把4字节当成4位了
加上性能探针跑microbench,再综合,最后记录数据

感觉涉及知识盲区了
不是哥们,还真找出一个错误?
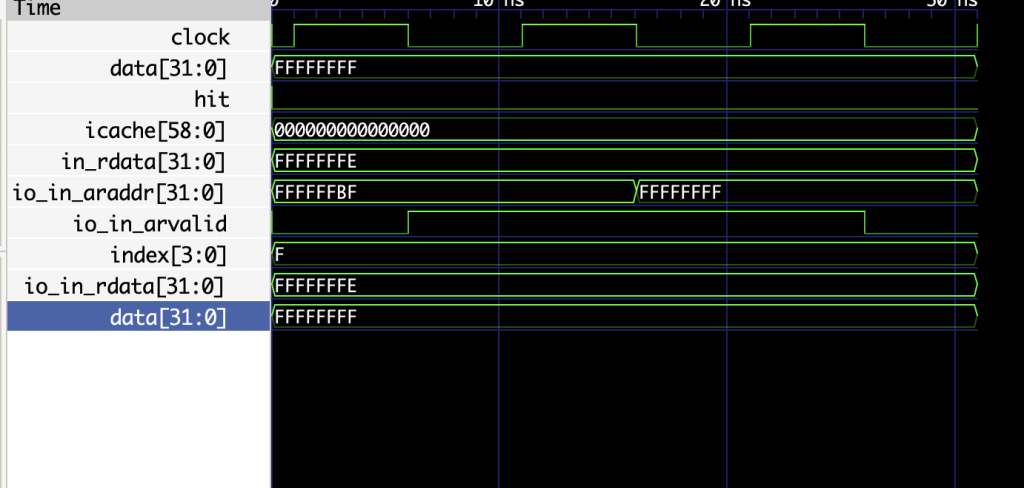
我不是很理解说实话,看这也没有hit呀,直接从中读不可能出错的,应该是我这个testbench写错了,因为这是刚刚reset就出错了,有一说一,testbench写错了那testbench怎么测呢?有点迷
不对不对,好像还真是我icache有点问题,只是这个问题基本上不会存在于现实的程序
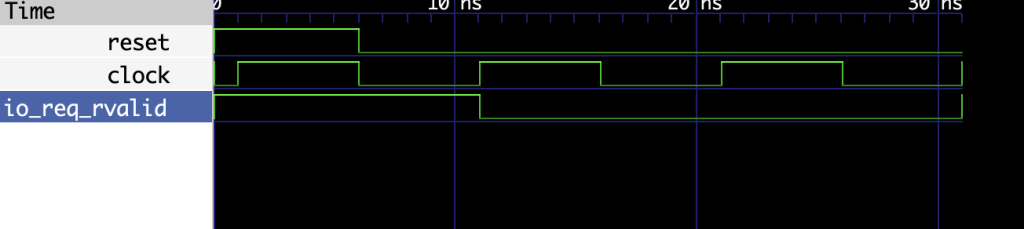
reset之后慢了一个周期,rvalid才置0,但是其实axi协议并没有规定这个,毕竟a通道都还没有握手,但是由于assert的条件就是在rvalid之下进行的,所以就assert掉了,但是实际上ar通道没有握手,上游模块不可能根据这个rvalid来取数据的,不过看了手册,这里确实还是不太好
改了一个又来一个
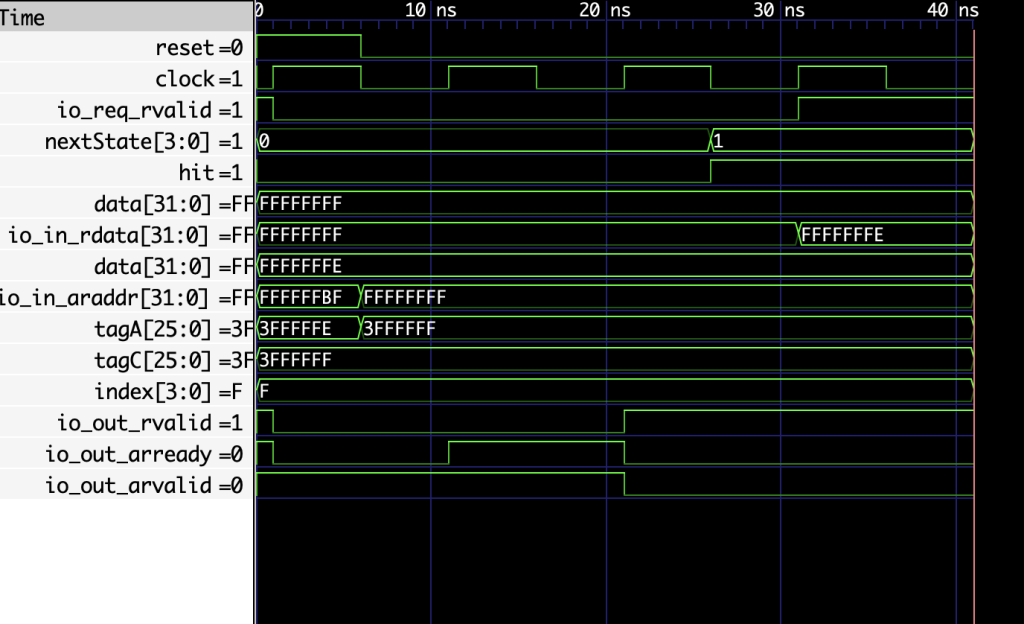
看起来像是在state为0的时候尝试从soc中读数据
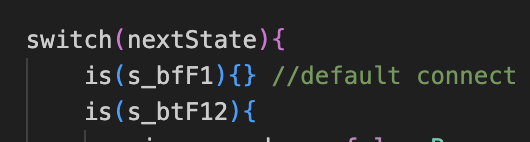
是因为我在这个状态下保持的in<>out连接,导致的错误,哇,太细了,太完美了,太牛逼了,这tm也能呗检测出来,我靠,这个说实话还真是我的疏忽,修改如下
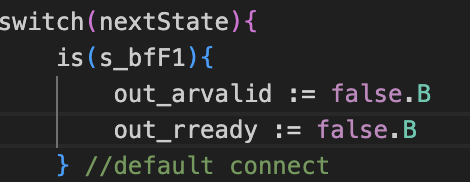
还是存在问题

从cacheData中读出的值和mem中的值不一样,是不是说明这个值在写入icache的时候出错了?
尝试将写入的值提取出来进行assert检查,但是并没有触发错误,没有写之前就出错,我越来越迷了
看起来像是cache没有初始化?no,我初始化了之后还是这样的,很奇怪很奇怪,令人无语啊(虽然很无语,但说实话,我真是爱死这个功能了,感觉他可以把每一个模块变得完美无缺)
感觉有点破防,不管了,不做这个了
缓存的优化
主要是提升命中率

简单需求分析:cachesim的作用就是读入itrace文件(只需要地址(由一个函数来实现细节,返回inst addr)),cachesim中需要有一个和真正icache有一样参数的cache(参数应该是可配置的)(但是其中只有metadata),对于每一个传入的addr,用cache的逻辑判断是否需要写入(即是否hit),累加hit次数和总次数和miss次数,最后得出结果。其实是比较直接的需求,很容易一眼看到背后的实现方式
想用c++来做,c++有4部分:c-c++,stl-c++,objective-c++,templete-c++。我想主要用第三个来实现
在做这个之前,我想先把trace文件做出来
nemu需要能读入并运行riscv32e-ysyxsoc的文件,最主要的难点就是两者的am不太一样,当然,nemu不用自己的am,但是由于am不一样,硬件上面可能存在一些地址冲突等问题,或者说ysyxsoc需要对串口进行初始化,但是nemu不需要,就会产生一些问题
之前为了使nemu支持ysycsoc的difftest,塞了很多屎到nemu里面,我现在想顺便清一下这坨屎,使nemu可以原生支持ysyxsoc,一举把difftest一些遗留问题给解决,还为之后可能的功能扩展留下一个干净的环境,其实就是改一下他的内存逻辑
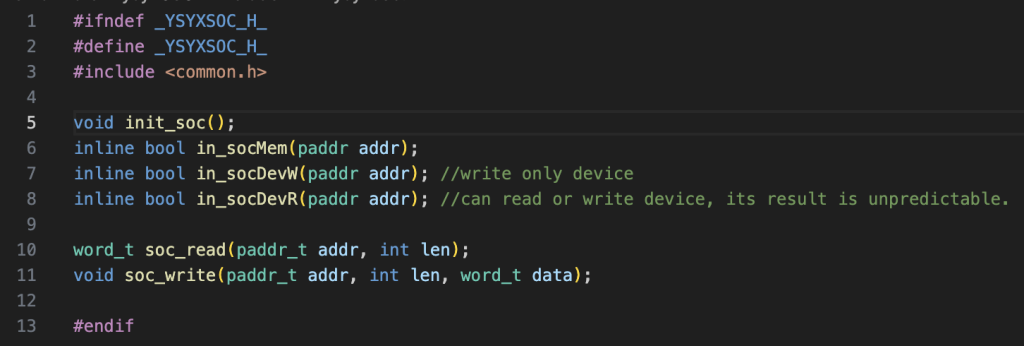
给上层的接口,有一种soc设备是可读的,但是nemu中不存在这种设备的,所以从可读的设备中读出值是未定义行为,如果是difftest需要在上层屏蔽这种行为,如果不是difftest这个问题就有点麻烦了,比如如果是ysyxsoc的am尝试轮训某个设备寄存器,nemu可能会对这种行为卡住,我需要想一个办法解决这件事,两个办法,第一个,在nemu中模拟,第二个,保证我输入的ysyxsoc程序没有对这种设备的访问
后者工作量更小,ysyxsoc在跑microbench的时候只会对uart和时钟设备进行访问,时钟的话可以随意返回结果,反正也就是结果不准而已,但是我也只是来获得itrace的,uart的话,最好要绕过这个轮训(啊啊啊啊好麻烦啊),用nemu跑ysyxsoc我觉得就是完全不合理的,但是这波要得到itrace还真得nemu跑(不然太慢了),本来想复用nemu的时钟的,但是感觉不想把nemu太多的东西牵扯进来,所以打算自己写一个简单的(反正也不需要很准)
还是打算简单实现一个时钟和uart的,uart读的返回值我就简单的设置一下好了(每次轮训都成功)
(nemu还是可怕的,哪怕我觉得我已经很熟悉它了,但总还是感觉这是一个庞然大物,有些很直接表达的东西被绕了很多道弯)
(草,nemu报错之后第一反应竟然是抓波形,感觉没有波形都不会debug了,但是nemu的抓波形其实就是printf)
报错是在bootloader中报的,通过一些笨办法,定位到是从flash 0x30003000处读出的值不正确了
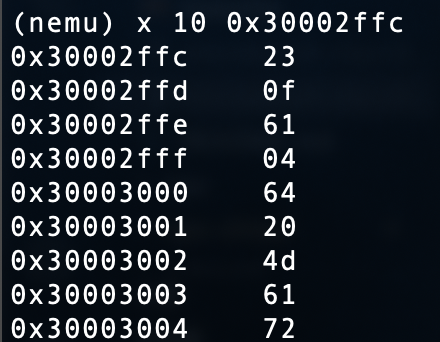

有两种情况,第一种,bin中的文件内容不对,第二种,没有正确load进去
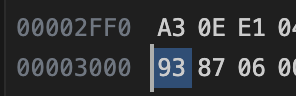
bin文件内容正确,只有可能是没有正确load进去
发现是flash太小,无语了
由于我的uart直接返回,所以与ysyxsoc可能需要的多次轮训产生的itrace可能稍有点不同,不过小问题啦

itrace有2.1G,我打算使用bzip2来压缩一下,因为这个popen这个东西我前几天才看过一眼(物理意义上的一眼)popen从一个cmd中读取数据,bzcat解压数据到stdout
之后需要写一个cache类,需要参数化它,参数分别是几路组相连
在此之前我要说一下这个w路组相联的概念的理解,首先offset一确定,说明确定了相应的块大小,也就同时确定了tag的大小,这是对内存空间做的第一次分类,tag就是组号,之后需要对着一堆内存块做第二次分类,如果是16个(按照前面的黄色任务点)(cache中的块数)分一组,就是一路组相联,此时index也就确定了,如果按32个一组分类,就说明每一组会有两个cache块,说明8个组可以放进一个cache中,此时一个index就不会一一对应每一个cache块了
其实第二次分类就是对一个cache空间内的cache块进行分类
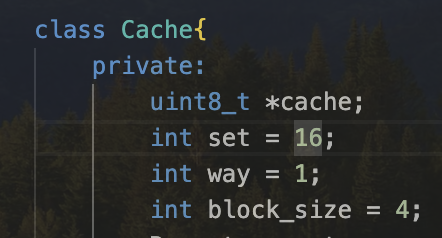
这些是他的参数(cacheSize = set * way),其实还有一个设计参数,就是替换算法,我希望做到替换算法能和整个流程节藕,比如做到一个callback函数之类的
但是替换算法如果仅仅变成一个在替换时(找不到空的块)执行的算法,他恐怕没有办法获得完整的数据,比如FIFO,面对一个index的多个cache块(本文不讲cache line,按照讲义的那一套讲为cache块),FIFO需要知道每一个cache块的更新时间,而LRU需要知道使用次数,Random则确实啥也不需要知道
第一想法确实是对每一个cache块建立一个类,在每一个类中维护这些值(使用次数,更新时间….),在hit,miss,empty等各种情况对cache块进行更新。
还有另一种想法就是对每一个index(cache组)建立一个类,在每访问一个组时执行替换算法,根据新来的cache块做对于组内cache块的重新排序(比如FIFO,一个新cache块请求访问一个组类实例,这个组首先判断是否hit,如果hit,则直接返回相应hit块,如果miss,则将这个新cache块的元数据(在真实系统需要做向下访存)尝试放入,如果有空位,直接放入最后一个,如果没有,则放入最后一个同时踢出第一个)(如果是LRU,如果hit,将这个hit块拿出的同时,将这个hit块放到第一个(最高优先级),如果miss,同样将其放入第一个,如果没有满,则皆大欢喜,其他的均往后移即可,如果满了,最后一个就会被踢出)
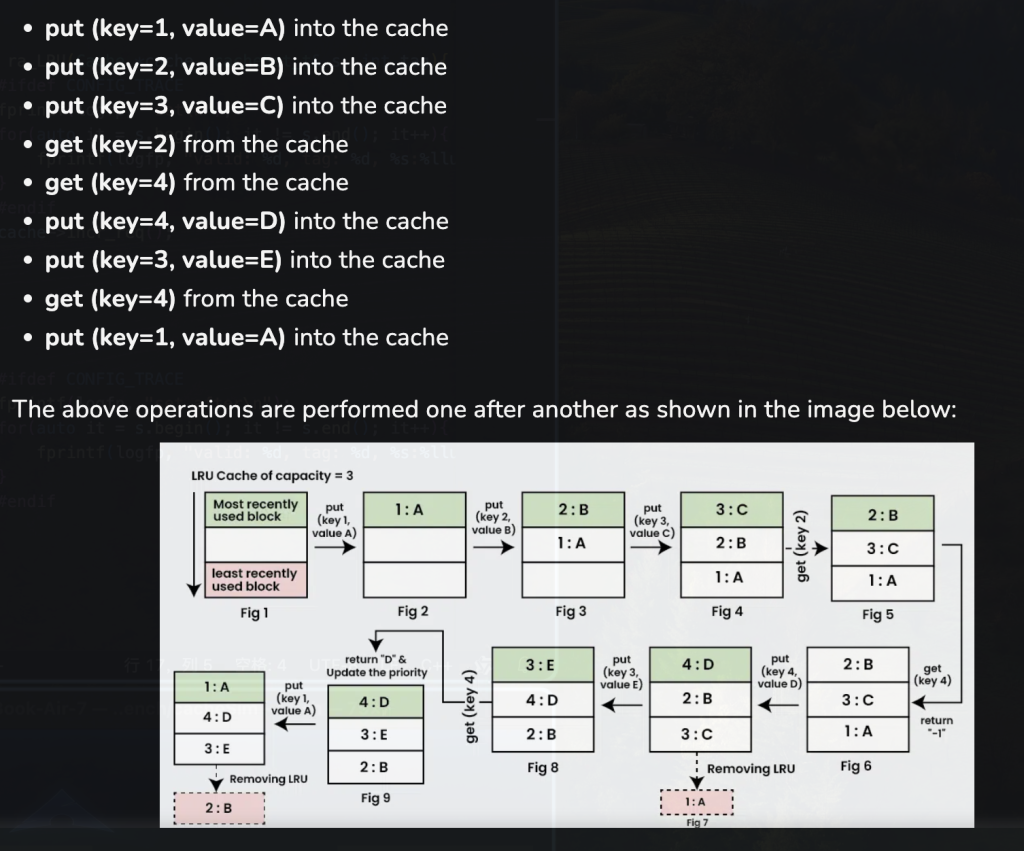
第二种方式不需要额外的对每一个cache加额外的元数据,从而减少了项目的耦合
第三种最蠢的方法就是在每个替换策略函数总维护一个元数据
我打算使用第二种方式来实现,实现细节:我想使用函数指针来实现,函数指针的参数首先必须是cache所请求的那个组的指针,再加上tag和offsett
果不其然一次写不对,尝试trace输出
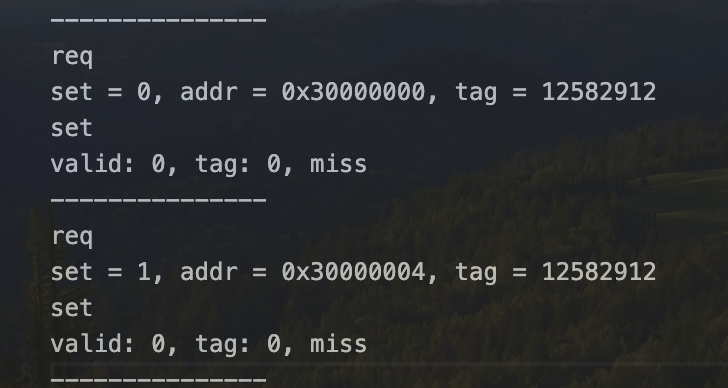
前几个tag完全一样,emmm,哦不对,tag一样很正常,我是sb,只能说tag一样的块index一定不一样
但是valid一直是0就不正常了,但是确实更新了,好好好,欺负我不会c++是吧,我有一个传参传的似乎是vector的复制版,需要传引用(我之前用的是指针,后面换成vector了(为了用std::rotate,所以我把他的行为当成指针了,辩护一下)
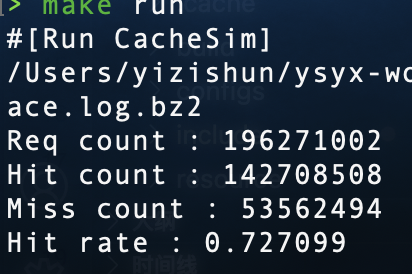

非常类似,之所以不一样取决很多问题,1,我nemu的uart和ysyxsoc的行为不同,2,每次程序运行走的分支都有可能不同,所以这是可以接受的误差,也说明我实现的80%没有问题,但是现在其实是全映射的,FIFO替换策略不能确保一定正确
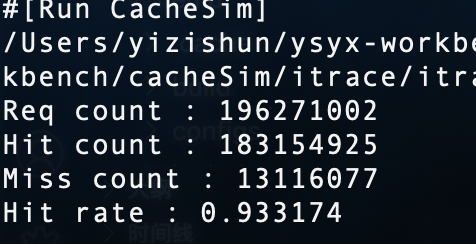
随便一试,在16个组,3路组相联的情况,可以达到如此高的命中率
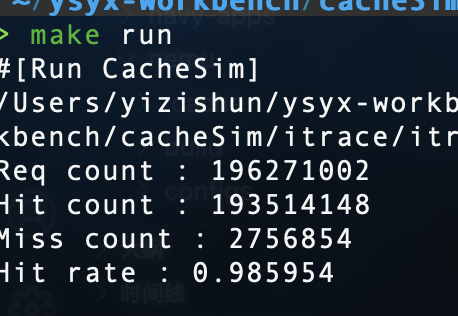
在上面的情况在增大块的大小为8可以达到98的命中率,但其实这时候的miss惩罚更高了

我原以为会变慢,但是变快了
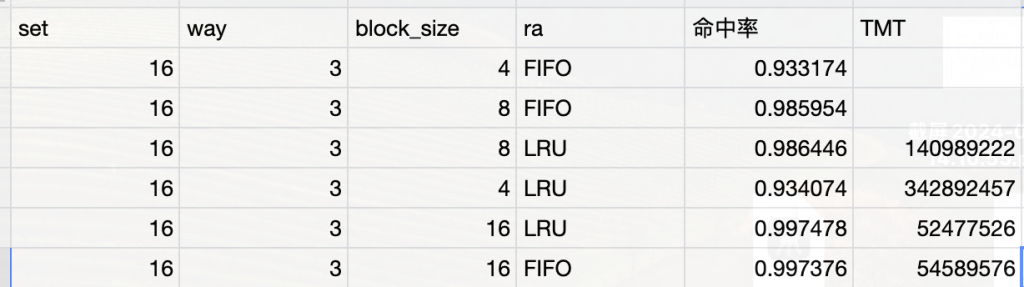


改成16字节一个block size,第一个miss,后三个全部hit,漂亮
遇到过一个坑,记录一下,我还是问的gpt的,我根本不知道怎么搜



如此写入icache中某一个set的data中的一个offset为x(这里是0)的地方,实际上根本写入不了
用gpt这种方法可以解决,我很迷惑啊,为啥我比不过gpt啊,我搜不到啊啊啊啊
草,我之后发现可以写入????,啊,为什么我之前试的时候不能,好吧,请读者忽略我上面的言论
之后发现可能是因为scala的类型很严格,导致有的地方类型不正确导致的
上面这一堆是我在上课时做的,感觉特别混乱,然后其实有挺多bug的,我需要全部清理一下
首先就是在一个地方出现死循环,抓波形发现有一段地址的inst不对
猜测还是cache的问题,在hit的时候却从cache中取出了错误的指令,像是cache写入的问题,但是miss毕竟是少数,我很难定位到写入的地方
通过一点努力,还是定位到了写入的地方,发现访问的地址的在cache块中的offset不是0,导致miss时我错误的将访问的地址全部当作offset为0写入,比如,如果访问0地址,我就会依次访问0,4,8,12的地址并写入,但是如果我访问的是4,正确情况应该是依次访问0,4,8,12的地址,但是我错误的访问了4,8,12,16的地址写入,导致写入错误
这个问题解决了,但是又出现一个问题

这个0?就很灵性,一看就是在串口处写入了错误的值,但是我的指令实现和am都不应该出错的,于是我还是猜测是cache的错误,但是有点难以定位到错误,波形结束前的几个指令都是正确的,这简直就是difftest最好发挥的时候,但是我difftest一直没有修好
发现是一个sb中的a2中的值是251超过了128,啊啊啊啊difftest就是秒杀这种问题
a2是由一条lbu指令修改的,说明内存出错了,太难溯源了,打算花点时间修修difftest了
修完difftest有一种感觉,想把读出来的inst也来比一下,但是不知道以后的需求,算了,还是觉得没有必要,定位到第一个错误点实际上就离真正的错误很近了
果然,inst还是不对,还是cache的问题
找到问题了,如果访问的miss是第四个:c,则访存顺序则是048c,但是当c的值出来后,还没有来得及写入cache就被读出了,所以读出的值是0

如何以一种比较好的方式解决这个问题呢?
有两种方式,这两种方式后面代表的思想很有意思
第一种,让rdata等待cache的更新,这叫做阻塞
第二种,让正在写入的组合逻辑信号直接传给rdata,这叫做转发
转发的时序更快,但是需要一些转发逻辑,就是面积会高,所以说,面积和时序是难以都满足的,所以需要做tradeoff,转发比阻塞快一个周期,但是需要比阻塞至少多一个比较器和一个选择器,阻塞还需要至少一个寄存器,比较器其实就是两三位的比较,很简单的,所以我选择转发
有一个小chisel坑,如果你使用for循环,并且有一个信号定义在外面,那循环结束之后这个信号的值将会是最后一次循环的值,但是如果你把信号定义在里面,他就会为每一次循环创建一个信号,可以讲scala语法当作c语言中的预编译器,两个行为很类似,但是scala语法比预编译器支持的语法更丰富
其实就是元编程,c++中最可以拿来炫技的东西在chisel中到处都是

改完之后,写内存bvalid就再也收不到true了…….感觉做ysyx就是在不断debug
之前是修改过控制器的代码的,但是我都忘记了,我觉得我需要先好好看一下控制器代码再波形溯源一下定位错误
有点不妙啊,我看我之前实现sdram颗粒的时候好像没有实现突发传输命令(这是后话了,我现在最应该做的应该是先把这控制器做好)
我之前在看这个代码的时候也总结过读verilog(HDL)代码的方法,但是我现在觉得那个方法是完全读懂的方法,但是其实HDL和正常的高级语言比如c不同的一点就是,c代码的逻辑是连续的,一般来说就是直接顺序向下读,遇到函数进去读,基本上整个逻辑就理清了,但是HDL不同,他没有一个总体的逻辑,他是每一个信号有每一个信号的逻辑,最多总体加一个状态机的逻辑,比如你在看前面的代码可能就需要一些后面才赋值的信号的值,但是从时间上来说,(代码)后面的信号可能比你现在看的代码赋值得更早,
所以我觉得就没有必要一开始把所有代码看懂,需要什么看什么就好了(前提是需要对整个信号的逻辑清楚),比如我就是bvalid没有,我就去找这个信号的逻辑,发现这个信号是三个信号的组合

然后看波形
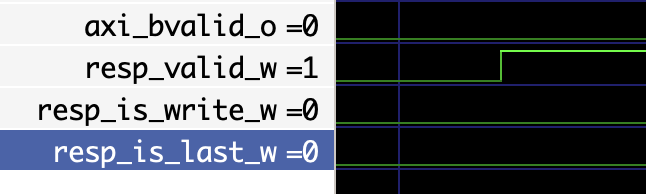
发现是后两个信号的问题,我就只需要递归的去追这两个信号的逻辑部分就好
看样子原因是我的wvalid持续时间太短了,但是不是只要握手成功了就可以置0了吗,有点迷惑,看看手册
似乎并不是这个原因

像是这个write_active_w的原因,感觉这个信号要持久一点才行
找到问题了,还是我的wvalid和awvalid持续时间太短,但是是因为awready信号在这边一直output为0,但是我的core接收到的是1,中间有延迟

从没有遇见过的错误,太诡异了,实际上在awready为0的时候,soc才真正从sdram控制器中读出值,但是经过delay到core时,awready还有很长一段时间的1,所以这时候如果awvalid置1就会导致lsu错误的进行握手(和一些延迟的垃圾信号进行握手),会导致awvalid错误的置空而不是进行等待,wvalid同理
我认为错误的根源好像是soc的awready为什么这么晚才变化,但是我觉得这是因为之前soc中的xbar把信号定位到flash里面了,导致要进行转换需要addr的切换

似乎还真是我的锅,要想确保soc给的数据是正确的,必须让addr以最快的速度出去
出去的信号延迟,进来的信号延迟,导致我lsu获得的信号实际上延迟了两倍中间的时间

但是手册上又说axi信号中间不能有组合逻辑,这该如何是好,我的master的addr变化瞬间,awready就变化了,我addr至少要经过一个xbar吧,awready也应该至少经过一个xbar,但是中间没有任何延迟,我不知道他是用了什么魔法,可以是转发?反正没有任何延迟,我打算将我的xbar和arbiter的寄存器全部拆了试试,草,我忘记了,我拆掉寄存器,我的状态机就会出现组合逻辑回环,我能不能做一些转发操作把信号提前转发出去?我就转发了一个awvalid信号,让他提前一个周期出去,结果就成功了?好奇怪,但是不应该正确的,我对整个aw通道信号进行了一波转发

既然我可以成功转发而不报组合逻辑回环错误,那么我之前的aribter和xbar感觉可以进行一波重构啊(我之前用的是状态机,状态机就意味着必须经过多个周期,我之后的重构是不是可以不使用状态机)
成功做到类似打洞转发的前提是转发的信号不能和控制状态机转移的信号相同,否则就会组合逻辑回环,这其实导致了不和状态机有关的信号过去了,但是控制状态机的信号没过去,导致不同步问题
于是我尝试将xbar和arbiter合并,发现chisel没有报错,但是verilator报错了,并且组合逻辑回环出现在一堆SoC信号中,我合并的原因就是因为xbar会操作arbiter的目的数据导致回环,现在合并之后中间依然还是没有一个寄存器,导致SoC中的代码操作xbar的目的数据导致回环
我懂了,其实只要soc的信号传回来的信号没有延迟就行啊,悟了
没有延迟的信号意味着core可以第一时间获取到信号,并且完全根据信号来在合适的时机发出信号
还是不太对,因为core发出的信号会产生延迟,还是会不同步导致问题,最终还是通过稍微有点丑陋的方式—因为在xbar中信号不存在延迟所以可以让xbar来插手握手过程
之后还进行了很久的debug,他有一个axi模块,有两个fifo,这两个fifo是axi请求和sdram回复的一个缓存,可能是为了同步两边以及支持burst吧,但是这里很容易出bug,我甚至发现了一个我做soc时修改的控制器的bug,主要bug就是什么valid信号,ack之类的信号如果只是想传输一次,就不要持续多个周期,不然就会被当成多个req/resp丢进fifo里面
这个地方debug了超过4天,终于还是在中秋节的那一天跑过了dummy.c

忽然发现flash不支持axi突发传输…….,所以需要在icache中判断现在的addr是不是落在sdram中
需要稍微修改一下我之前写的sdram颗粒的实现,最终的波形示意
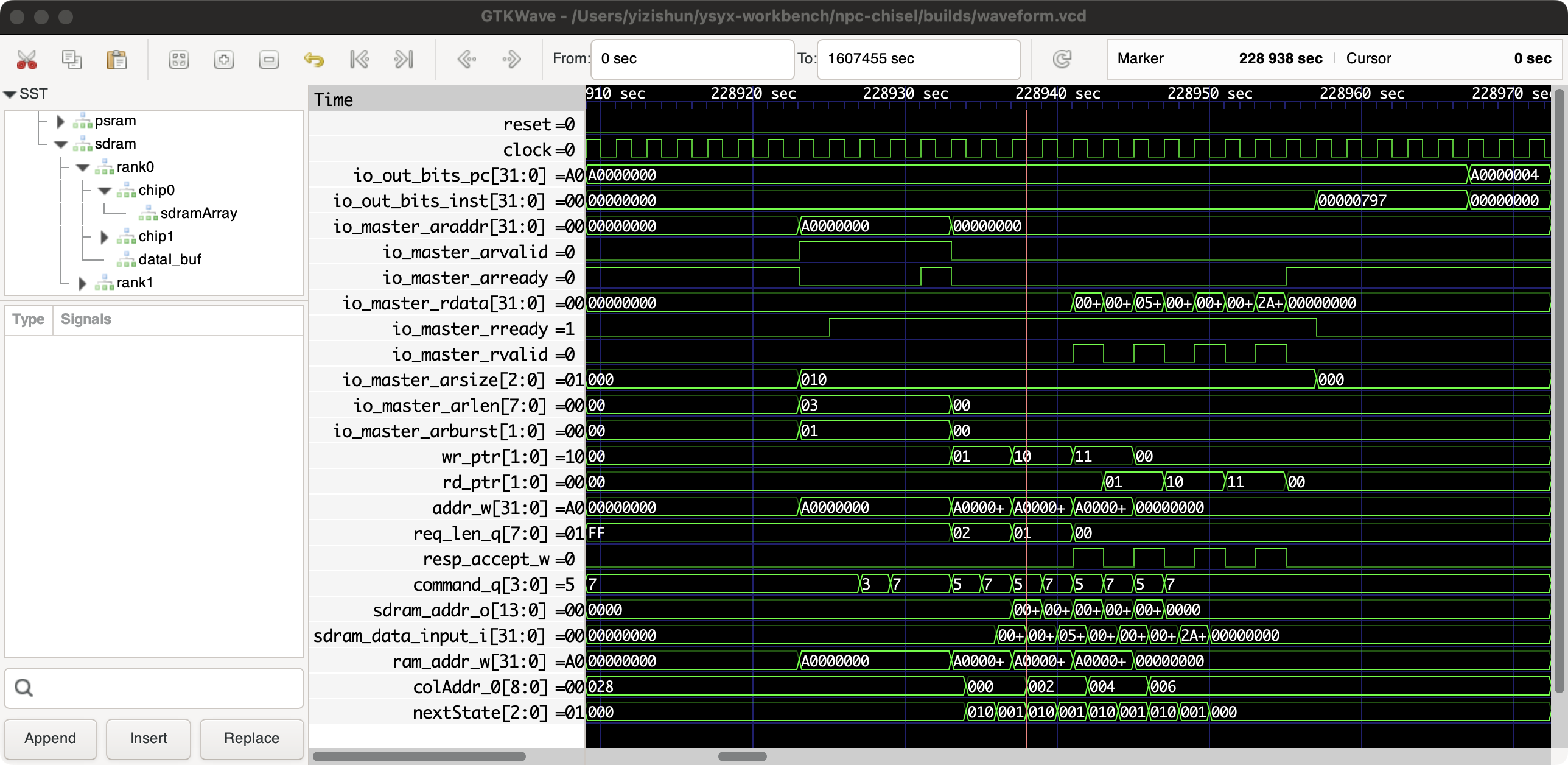

如果要严格做的话,应该是ar,aw,w通道的握手全部要校准,比如awready被delayer接收到,需要延迟返回,However,似乎并不需要这么做,这几个通道我觉得完全可以直连,只将回复的那几个信号做延迟,比如bvalid,rvalid,rdata等,让我想想这样可不可以,感觉严格来说不可以的,比如可能master接收到awready才将bready置1,如果直连的话bready信号会更快到来(当然这是只是打个比方)但是真的这么做还挺麻烦的,每次从out接收到值都需要做一个标记,反正感觉逻辑会复杂很多倍
写给明天的我:我现在已经把写的通道延迟差不多校准完了,读需要一个burst逻辑,我已经可以记录每个out.r.fire的具体delay了,我现在需要做的是根据这些来发出对in的rvalid逻辑
遇到了一个bug,一个arvalid信号通过第一个axixbar时没有把这个信号传过去,这个xbar连接了sdram和xbar2,但是在master有arvalid信号时,两个slave都没有相应的arvalid信号,但是araddr确实是正确的,于是我打算花一点时间看一看rocket-chip的xbar实现(小小300行,不足为惧)。。。。。哎,有的300行很简单,有的300行确实难如登天,每一句话都读不懂,还是等我多学学scala和chisel再来读吧(龙芯杯之前一定要好好读读写的好的chisel源码)
之后发现是没有正确的置rlast,通过与没有delayer的做比较,也算是一种difftest了
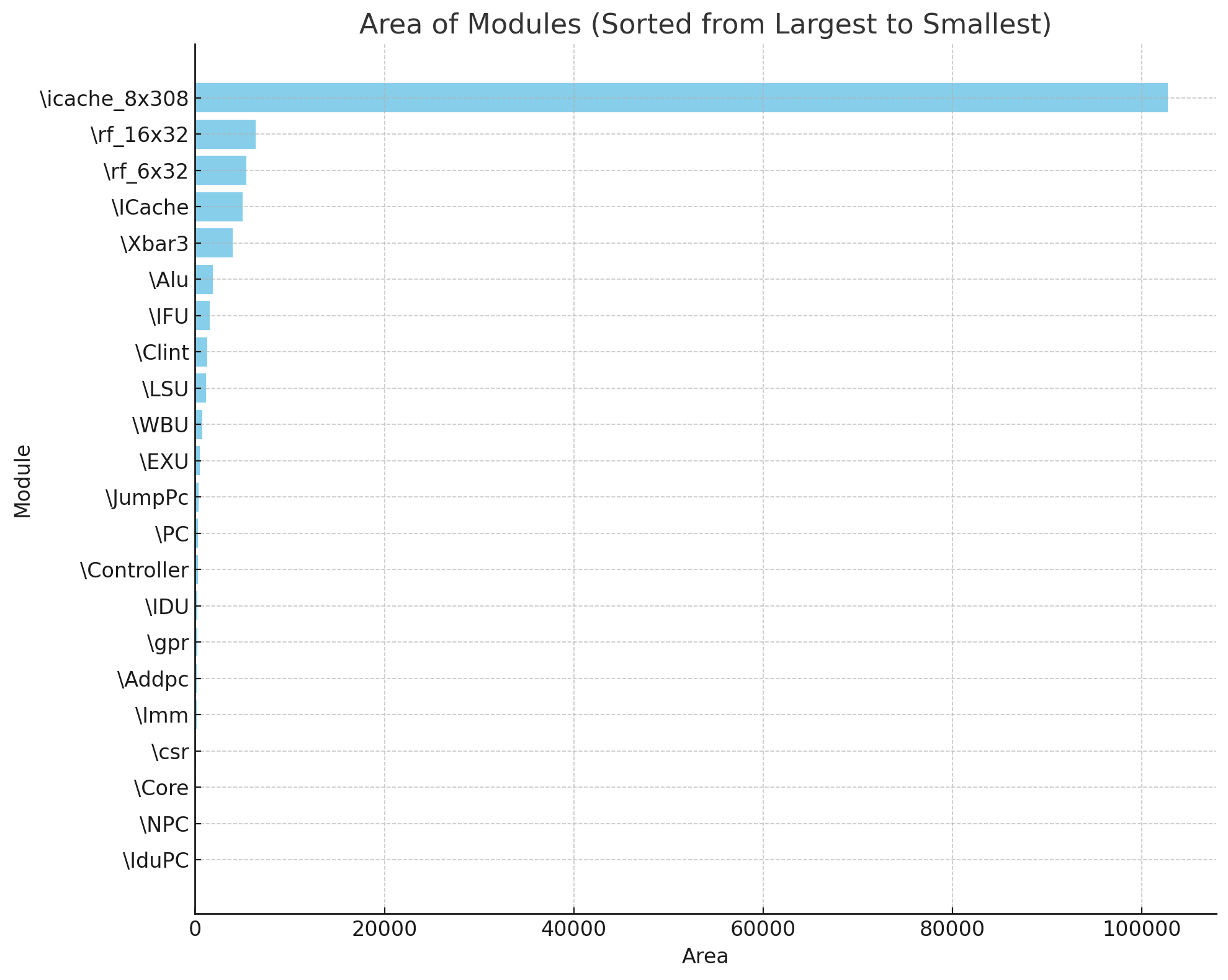
之后综合面积爆炸,icache面积有10w,列一下面积
- ‘\Addpc’: 158.802000
- ‘\Alu’: 1846.572000
- ‘\Clint’: 1302.868000
- ‘\Controller’: 320.530000
- ‘\Core’: 90.706000
- ‘\EXU’: 524.818000
- ‘\ICache’: 5006.120000
- ‘\IDU’: 260.946000
- ‘\IFU’: 1546.524000
- ‘\IduPC’: 36.176000
- ‘\Imm’: 149.758000
- ‘\JumpPc’: 375.326000
- ‘\LSU’: 1168.538000
- ‘\NPC’: 40.964000
- ‘\PC’: 328.510000
- ‘\WBU’: 770.868000
- ‘\Xbar3’: 3947.440000
- ‘\csr’: 125.020000
- ‘\gpr’: 210.938000
- ‘\icache_8x308’: 102723.348000
- ‘\rf_16x32’: 6411.664000
- ‘\rf_6x32’: 5416.558000
‘\NPC’: 132762.994000
除了几个寄存器堆,其余最大的就是icache,xbar3,alu,clint
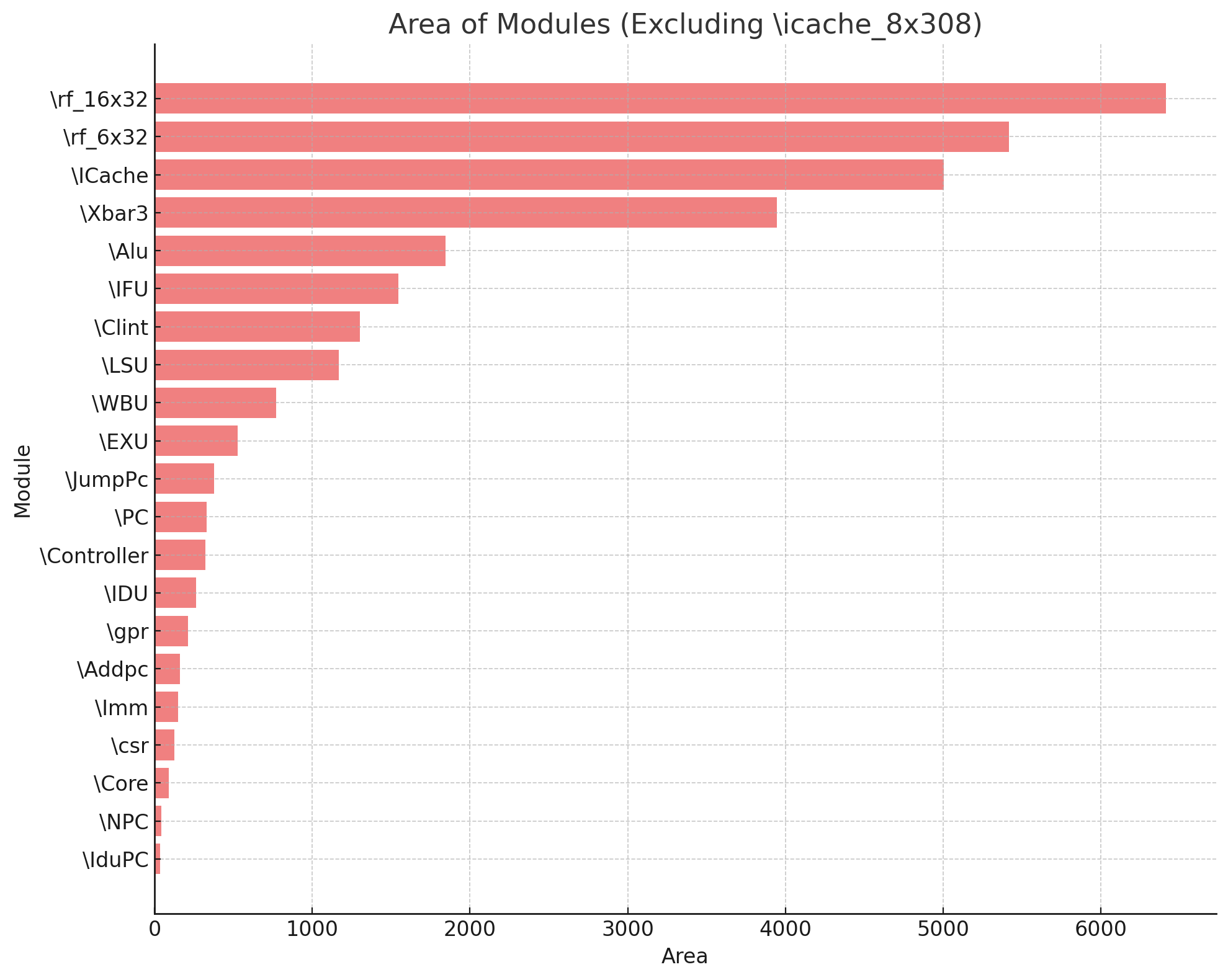
看起来优化的方向有了,但是我现在的目标是感觉做完,所以我打算做完流水线再进行优化
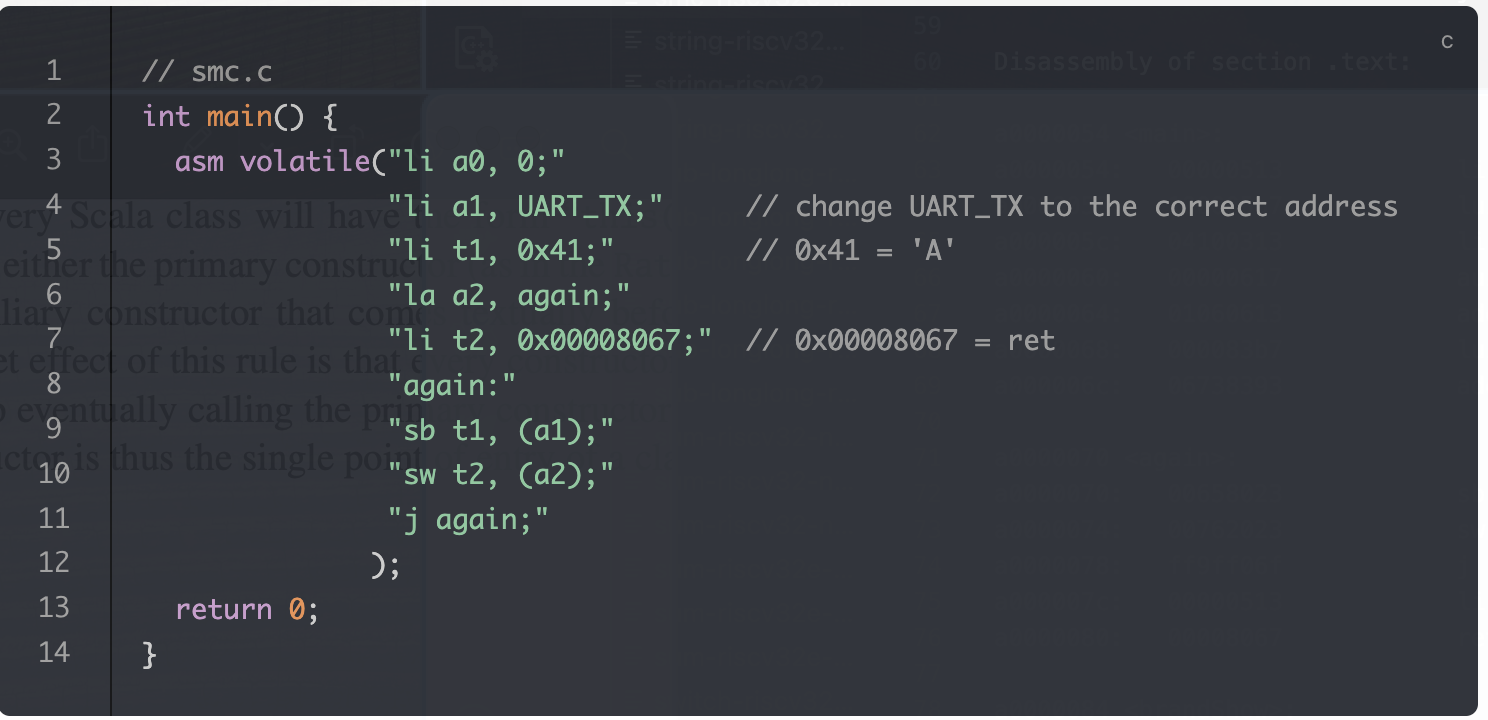
这个代码的预期行为是只输出一次A,但是最后却是一直在输出A,主要就是icache中存了未更新的指令副本
riscv中规定了一条fence.i指令,这条指令类似一个栅栏(fence),我猜测他的全称是instruction fence,在这条指令之后,上层可以保证之后取到的指令是全新的,至于具体实现有很多种,讲义给了几种
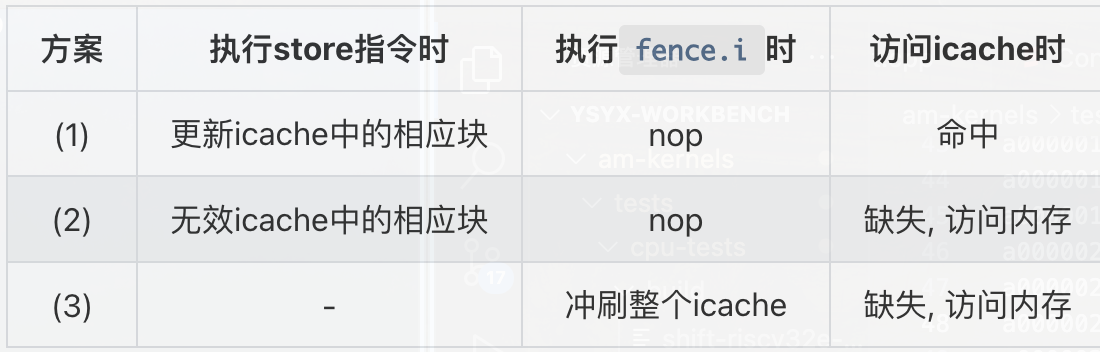
我如今作为一个硬件设计者,我当然希望实现更简单,也就是执行第三种方案,将所有icache的有效位置0

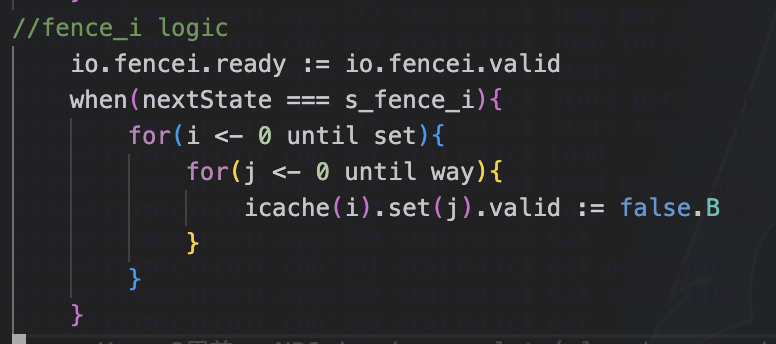
不知道为啥我是只想让valid为0,但是波形显示全为0了,无所谓了,反正冲刷成功就行
The end
其实没有完结,我看了一下说是icache的寄存器堆的面积也要算到总面积里面,有点不妙,我需要减少icache的容量,虽然说我现在没有优化面积的打算,但是icahce实在太大了,我觉得我至少得要优化到3w面积左右再开始流水线会比较好
我的icache由于支持n way组相联,导致icache的本身的面积也挺大的,话说块大小为4,那我改成axi的意义在哪,将index从8改成了2,块大小8字节,1路组相联,命中率肉眼可见的掉了,直接变成40%的命中率了(当然我还没有做设计空间探索),但是面积变成3w多一点了,三个寄存器堆占了1.5w,这里是很难被优化的,所以需要优化其他部分,将其他部分合力优化5k(频率还降了,我好菜啊)
让我做一些设计空间探索,在此之前,我需要

记录一下:
4的块:28.782574(我发现2index4块大小的命中率是0…..)
8的块:36.106663
16的块:52.820628
好的,开始cachesim
记录一下:
- 8,2,16
178649875.200972
0.982768 - 4,4,16
157052682.465588
0.984851 - 4,4,8
609625836.865238
0.913976 - 2,1,8
4543847518.567875
0.358820 - 2,2,4
4547736551.196028
0.194975 - 1,1,16(全相联)
3841929400.189944
0.629413 - 1,2,16(全相联)
1733781388.337460
0.832762 - 2,1,16
1607972582.719524
0.844897
8097.040000(2×156) - 2,2,8
1580788448.589399
0.776936
14082.838000 - 4,1,8
1568175271.896946
0.778715
14371.182000(4×92) - 2,2,16
1110082385.236356
0.892923 - 8,2,4
2130683144.199030
0.622834 - 4,2,8
1147069327.247330
0.838138
面积都很难让人接受,我觉得可能是我打开方式不对,我应该换一个方式写
14371.182000(4×92)
6310.052000(16×32)
两种寄存器堆,前者更小但是面积更大,我打算自己探索一下
我有两种猜测:1,第二个需要是32的倍数综合的面积会小。2,需要宽和高接近面积会更小
开始验证猜测
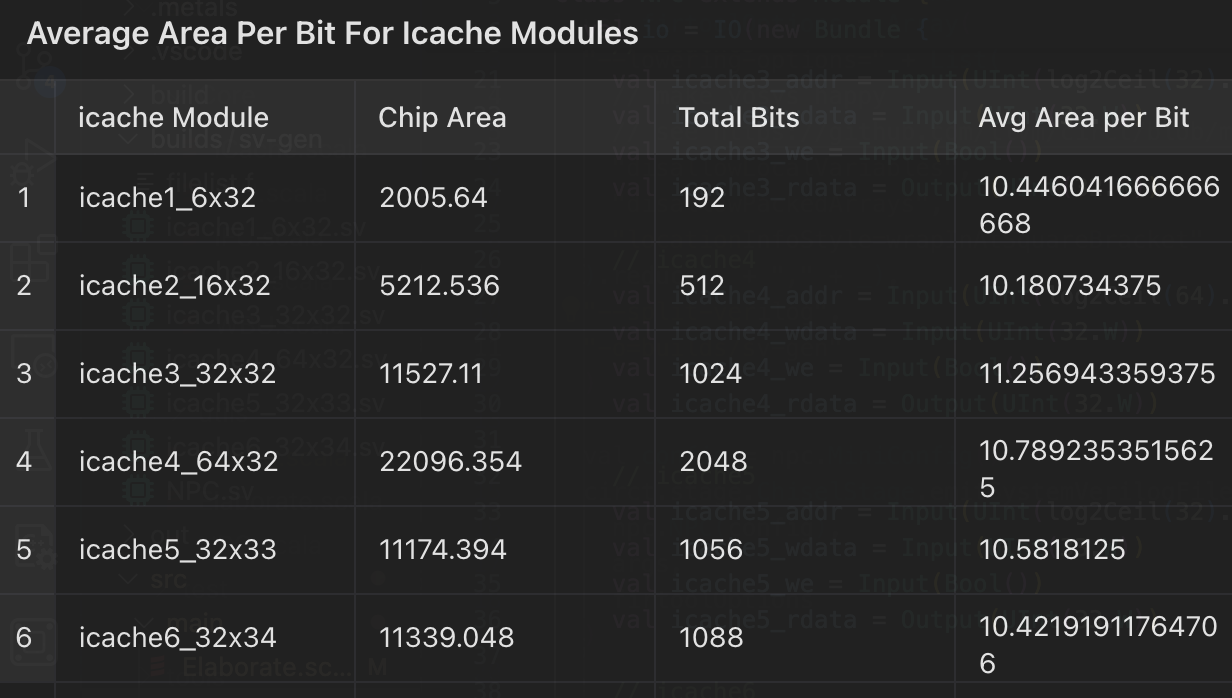
看上去很平均
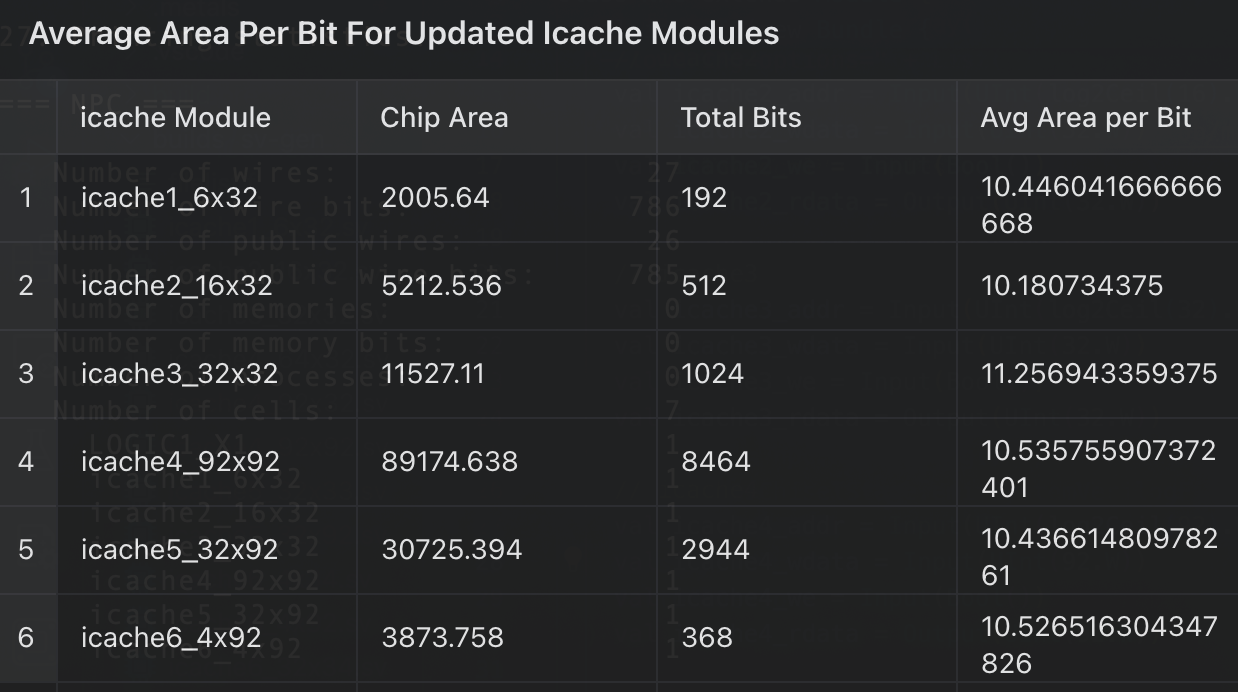
看来我的两个猜测全部错误
真正占高面积的是很多的BUF,MUX等,通过看verilog,发现我的icache读写端口有点多
分享一个网址:DigitalJS Online (tilk.eu)

超多的读写端口导致的高面积,为什么我的chisel会产生这么多读写端口?
优化的时候出现了一个非常好的时间换空间的操作
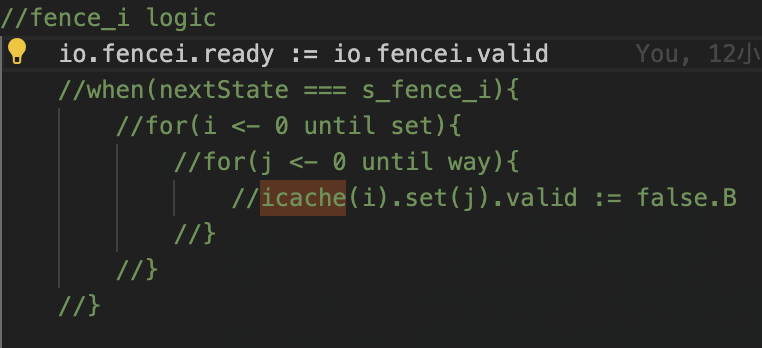
我的fencei逻辑会在同一时间写icache,这会出现四个写端口,但是我注释掉之后却只有1个了,但是想要实现通过一个写端口实现fencei,就必须多花3个后期来写,但是面积瞬间掉了3k,无敌
我发现用reg,mem综合器都把他综合成DFF
这种综合我该怎么学啊
我去搜了搜教程,看到了一个mooc教程看起来还不错

推荐了一堆书目,感觉可以稍微看一下,学习一下(现在在看其他书,打算做完流水线开始看这些书+超标量处理器)
其实我最后的icache参数是4,1,8,面积大概优化到了2.9W,感觉我现在的主要任务还不是优化这些,而是先完成后完美,做完流水线再说
完结