
前言:以下为我做ysyx的soc的每日记录,叙述以黄色任务为主线,基本无参考代码,大多是一些每日吐槽(狗头
接入

第一个任务的第一小点就如此炸裂
分一下步吧
1,读手册,找出每一个信号的作用(x是r或者w)
- axid 感觉是为了可能的无序传输设置的id,需要对应后面的xid
- axlen 这个决定了需要传输多少次
- axsize 这个决定了每次传输的总字节数,而wstrb决定这些字节中哪些是有效的
- axburst 决定了传输的type
- xlast master最后一次发送数据时需要assert这个信号
- xid 返回数据的id
分享一个讲的比较生动的链接(这手册写的挺好的,就是我英语不太好看不大懂)AXI Burst Size meaning – SoC Design and Simulation forum – Support forums – Arm Community,讲的是axlen,axsize,axburst
我感觉这些都是一次需要传输很多数据的情况,我现在暂时想不到这方面的需求,最大的lw指令也只是一次性传32个字节,所以axlen可以一直为0,xlast可以一直为1,axid以及xid可以一直是0,axburst一直是INCH(0b01),唯一需要注意的是axsize需要根据需求进行设置(特别是对于设备的访问时更需要注意)
基本SoC

记得不是gcc,而是riscv-…..-gcc,objcopy同理,可以参考am的那个经典makefile
寄了,这个总线的行为怎么跟我想的不一样
嘶
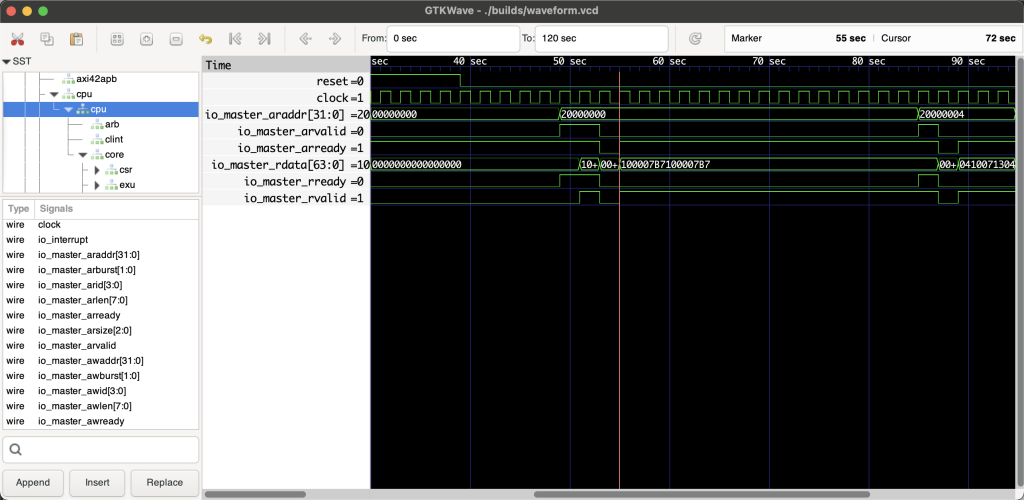
这种波形真的是对的吗,就我这红线处,我arvalid和rready都是0的情况下,为什么rvalid会变成1
在群里问了一下,ni佬看出了我的问题(膜佬
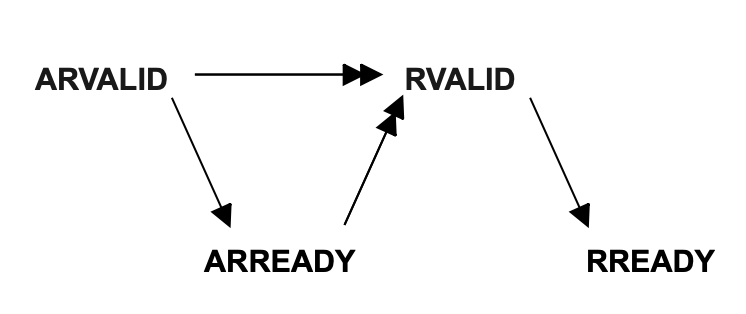
这个图要看仔细一点,文档里面很少有地方写rready的dependency,上图是一个地方,另一个是
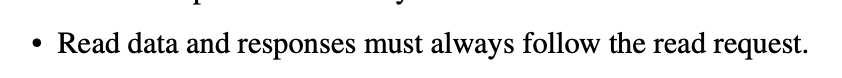
也就是rready需要等第一个ar通道握手之后才能置1,哎,应该所有人都会想当然(如果不仔细),毕竟master能接受数据不就随时可以把rready置1吗,但是不是这样的
相应需要改的还有lsu的bready

虽然我并不记得pa有讨论过这个问题……但是之前做pwn题时这个还是比较常见的,有个东西叫做行缓冲,也就是glibc的输出函数有一个缓冲区,只有刷新缓冲区时才会输出到屏幕上,刷新的时机我知道的有三个:1,缓冲区满了;2,遇见了换行符;3,fflush()手动刷新


链接的知识真的都忘掉了,于是我打算再看一遍视频
之前编译char-test的时候从c编译到bin会出现对内存的写入,所以我直接手写了一个.S然后编译到bin。
虽然没什么缘由,但是上面的经历让我对ELF的文件又理解了不少,c编译链接到ELF,里面不仅有数据和代码,还存在元数据,这些元数据指定了代码运行的“环境”,如栈区,堆区,程序入口,权限设置,甚至还有调试信息,这些元数据被不同的其他工具利用,如调试器利用其中的调试信息,动态链接器利用程序入口和权限信息加载程序等等,确保程序的代码和数据能在一个“安全舒适”的环境中发挥作用
但是bin程序没有类似的环境,于是他是否需要自力更生,让自己的代码不去触碰违法的内存地址,于是需要设置很好的编译链接选项编译出好一点的指令序列
第一个任务没有太大的难度,copy就行
第二个错误是因为对于mrom进行写入,原因是c代码有对全局变量进行写入的操作,但是全局变量存放在data section或者bss section,data section被加载进内存之后属于mrom,所以还需要将data段放在sram中,修改链接脚本
但是这会导致text和data之间差了一个巨大的空隙,会导致bin文件特别大,甚至直接触发了我仿真环境的assert
嘶,我改大了仿真的mem之后还是会卡住,看了一下读出来的指令都是错误的,我hexdump了一下,发现bin文件的前几个字节就是错的,难道是objcopy有问题?
我再次hexdump了一下bin文件,发现前几个似乎是数据,我拉到最后,发现最后才是代码
因为我的链接脚本是这样写的
但是entry确实设置的是0x20000000,但是hexdump时似乎就是按顺序来的,我知道了!!!
我需要把我仿真环境的mem的结构也改成符合设备的内存布局,我现在起始地址是0x20000000,但这其实只应该是text段的起始地址,真正的起始地址应该(暂时)是0xf0000000,然后把entry地址改成0x20000000,即从这个地址去指
不对!哎,把bin文件全部读到仿真环境没有用啊,要把数据等东西读到sram里面才行呀,因为全局变量里面有数据…..哎,这可怎么整啊,我觉得在mrom里面的代码就不应该存在全局变量,这种地位的代码应该充当将其他代码加载进sram的功能,也就是传说中的bootloader
算了,放弃这个任务了,反正也不是必做题,

MROM和SRAM的属性有点不同,一个不能写,所以还是别复用nemu原有的内存吧,既然访问内存都是通过pmem_read/write,那就只需要在这两个函数中对地址做一个判断,从而调用mrom_read,sram_read/write即可,最后发现只需要修改guest_to_host函数即可,只能说nemu的可扩展性真的很高
加完difftest之后发现不知道是不是sw还是lw指令有点问题,lw指令读出的一直是0,但是sw之前确实有存,由于ifu能读出指令,合理怀疑是sw的问题

太坑爹了吧,FD0和FD4都是对应的一个地址(1FA),之前一个群里面一位兄弟就感概过这个问题…..现在自己遇到了真是很感慨万千啊
也就是sram的一个地址间隔是8个字节,所以wstrb必须指定写入这个8个字节的那几个字节
经过漫长的debug,终于能过所有不对全局变量写入的cpu-test了

先看看手册吧,包括axi的resp和riscv特权手册

也就是添加1和5和7,分别对应于rresp(ifu),rresp(lsu),bresp(lsu)
这个irq的机制我之前没有实现得很好,主要是我没学过,我也只能靠猜想
我把每个模块都写5个irq的port,一个出四个进,然后在Core模块直连,也就是一个模块产生irq,4个模块都会立马收到,并且一旦受到,就将自己的状态变为default状态,pc也会在下一个周期改变,也就是所有全部状态都变成刚开始的样子了

一个下午做了个这个,效率好低。。
这个要注意内存分配,链接脚本的栈地址必须对齐4B,并且最好不要超过0x0f001fff

static链接的程序我们普遍会认为他很大,但是通过给编译器 -ffunction-sections -fdata-sections这两个选项可以把程序的每一个函数/全局变量分一个section,然后给ld传一个优化选项–gc-sections把没有使用的section去掉,以减小elf文件的大小
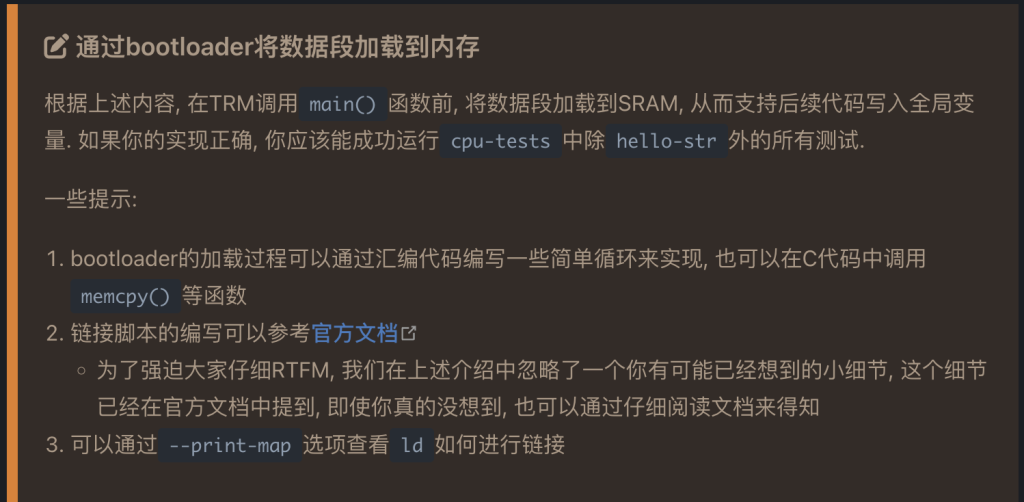
这个小细节是啥捏,我猜测最有可能的是当定义了一个区域的话,section里面的符号声明是按照VMA来还是LMA呢,正确答案是VMA,那我该怎么知道data在LMA的地址呢,一个方式就是显示的标明他LMA的地址,还有一个可能是把data段放到sram里面会把之前的heap和stack地址覆盖
ENTRY(_start)
PHDRS { text PT_LOAD; data PT_LOAD; }
MEMORY {
flash : ORIGIN = 0x30000000, LENGTH = 262144K
sram : ORIGIN = 0x0f000000, LENGTH = 8K
}
SECTIONS {
/* _pmem_start and _entry_offset are defined in LDFLAGS */
. = ORIGIN(flash);
.text :
{
*(entry)
*(.text*)
_etext = .;
} > flash AT >flash : text
etext = .;
.rodata :
{
_rodata = .;
*(.rodata*)
*(.srodata*)
_erodata = .;
} > flash AT >flash
.data :
{
_data = .;
*(.data*)
*(.sdata*)
_edata = .;
} > sram AT >flash : data
.bss :
{
_bstart = .;
*(.bss*)
*(.sbss*)
*(.scommon)
_bend = .;
} > sram AT >flash
_stack_top = ALIGN(0x10);
. = _stack_top + 0x800;
_stack_pointer = .;
end = .;
_end = .;
_heap_start = ALIGN(0x10);
_heap_end = _heap_start + 0x400;
}
最终可以跑除了hello-str的所有cpu-test的链接脚本(上面这个显示好像有点问题)

讲义这里似乎有点问题,做到这一步时,还没法运行am-test,因为太大了超过mrom的大小了
至于没有输出全部字符,我数了一下到底输出了多少个字符,正好16个,一个字符一个字节,16个字节,是不是存在一个什么队列的东西满掉了
ysyxSoC的源码我迟早得看的,里面肯定有很多chisel的高级用法,偷学一点用到npc上也是很好的,但是这个会cost很多时间,最近又临近期末考试,不!一定要认真看源码,我感觉我的npc写的太烂了(指可扩展性和可读性)
看了一下diplomacy框架写的总线,虽然有70%看不明白,但是看他这个框架写出的代码还是蛮漂亮的

node可以简单理解为模块的端口,这几行代码还是比较生动的展示了soc的连接关系
之后看verilog的uart代码,1000行左右,摆烂了,随便看了一下

除数大概是对于clock的一个削减?以适应uart的传输速度
我把除数设置为300,发现只能输出17个字符,索性直接设置为1了
bug修复:之前LSU发出的写地址永远都是对齐4B的,导致我无法对0x10000003这个地址进行写(本来是使用wstrb来写这个地址,但是uart模块直接忽略掉了wstrb),更改为LSU发出的写地址无需对齐任何边界,而对齐这个责任应该是设备或者是soc总线的责任,我只需要负责wstrb的正确设置,读地址本应该也要遵循这个的,但是我还有一点没想明白,我打算遇到了问题的时候再想这个读地址的问题

设置为1时不会出现上述问题,因为串口速度很快,不会出现满掉但是还在填充队列的情况,但是设置为10就会出现上述问题,所以需要软件(也就是指令,也就是cpu)等待串口发送
这个地方我原本有点主观臆断了,还在qq群问了,我之前觉得读0x10000005这个uart寄存器返回的值就仅仅是这个寄存器的值,但是似乎他返回的地址也被总线对齐到了0x10000000,方便了用一套方式选出数据
最后我设置了300的除数,可以看到字符一个一个慢慢的被打印到屏幕中
FLASH

这个实际上是要把MROM给优化掉了,通过RTFSC,在不使用SPI总线协议时,flash颗粒定义在ASIC模块内部,并且只支持一个command,也就是写指令,用spi模块充当flash控制器,向flash颗粒发命令

好坑好坑好坑好坑好坑好坑好坑好坑好坑好坑好坑好坑好坑好坑!!!!!!
两个坑点:
1


ctrl寄存器的Tx_NEG和Rx_NEG的行为是反的(你第一眼看出来了吗?)
2,该spi是全双工(full duplex)通信的,但是讲义的说法有误导性,让我误以为是半双工通信的,半双工通信意味着在前8个clock仅仅只进行MOSI的传输(假设传输为0xAA),结束后RX/TX寄存器为0,后8个clock进行MISO的传输,将RX/TX设置为0x55,此时读这个寄存器即可
但是全双工完全不一样,读写可以同时进行,那可能就会自然而然产生疑问,既然可以同时进行,那我设置的传输大小只需要8不就行了?但是由于目的行为是进行位翻转,需要完全得到MOSI的数据之后才能传输MISO的数据,也就是说在前八个clock逻辑上是仅仅进行MOSI的传输,但是,行为上,与此同时也在进行MISO的传输,也就是在前8个clock,RX/TX寄存器的前八个bits里面的值逻辑上是无效的,因为在后8个clock才进行MISO的传输,传输结果在后8个bits中,所以在软件中需要对读出来的RX/TX寄存器中的前八个bits进行移位消除

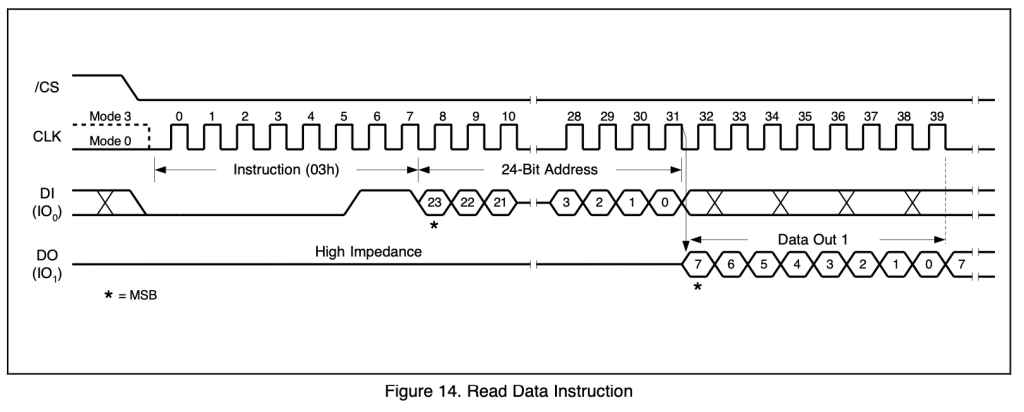
现成的图,不知道为什么我的波形和上面的有一个不一样的就是在DI传输数据时,DO是0,但是图中是1,但是似乎不会有什么问题,我也不知道具体的原因,我打算之后出问题的再来解决这个问题
他第一个bit获得时会放在MSB,所以最终获得的数据就比较直观

由于获得的bits首先会被存放在MSB中,所以就会出现低位字节存储在高位地址的情况,这是大端序,但是其他程序都是小端序的,在执行的时候就会出现问题,于是需要在软件中修改一下

看之前我还以为是要改NPC的IFU,但是是改soc的代码,为我的npc提供了很好的抽象,因为cpu应该是要通用的,不能因为设备的不同而修改cpu的代码,cpu最多就是适配一下soc总线的宽度
做的时候感觉头脑很混乱,还是时序的问题,这几个协议的时序配合不好,画了个图

当接收到来自master的apb指令时,一般来说就是直连spi controller,但是由于我们要实现flash-read,我们需要接管这个信号,解析这个来自master的信号,然后使用另一种方式访问spi controller,当然,中间需要完全接管两边的信号,所以需要对apb协议有所了解(到这里真是学了很多不同的总线协议了呢,写完SoC汇总一下)
666,竟然一遍写对了,还是一个比较复杂的状态机哈哈哈哈

链接脚本,差点忘了,看波形发现死在一个sw指令了才想起来
草,为什么跑cpu-test一堆bad trap,好烦呀
我发现还是地址对齐的问题,让我梳理一下,现在sram对于0x0-0x8(0-63)是对应同一个地址,0x8-0x10对应的是同一个地址,八个字节一个对齐,然后我默认他回复的值也是根据8字节对齐的,所以我会进行选,但是Flash返回的数据并没有遵循这个8字节对齐,访问0x5回复的就是0x5的值,但是Flash使用是apb协议,他rdata最多只有32位,怎么表现出这种0x5的位置出来呢,我看了一下uart(因为他也是用的apb),他将返回的值复制4次,因为访问uart寄存器最多也就是1byte,它把这个1byte复制4次到32位,比如0x71,就变成0x71717171,然后之后被扩展到64,就是0x7171717171717171,也就是说我需要在flash的代码中对读出的数据根据strb进行处理,草,上面这段文字是我边上课边写的,有点晕,strb是写的时候才会设置的,我是sb,想着使用arsize,但是发现在AXIToAPB时并没有使用arsize,这该怎么办捏,最后我用移位来解决的,就是和LSU的移位反过来就好

RAM

感觉好复杂啊,这就真的是根据手册实现出一个阉割版的IS66WVS4M8ALL颗粒,并且没有任何的框架,最主要的是不敢写,我已经发呆两小时了
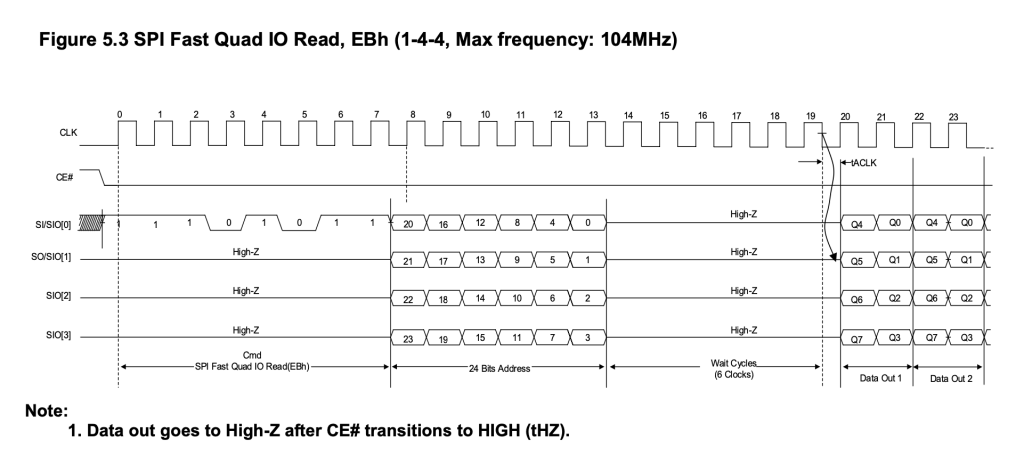
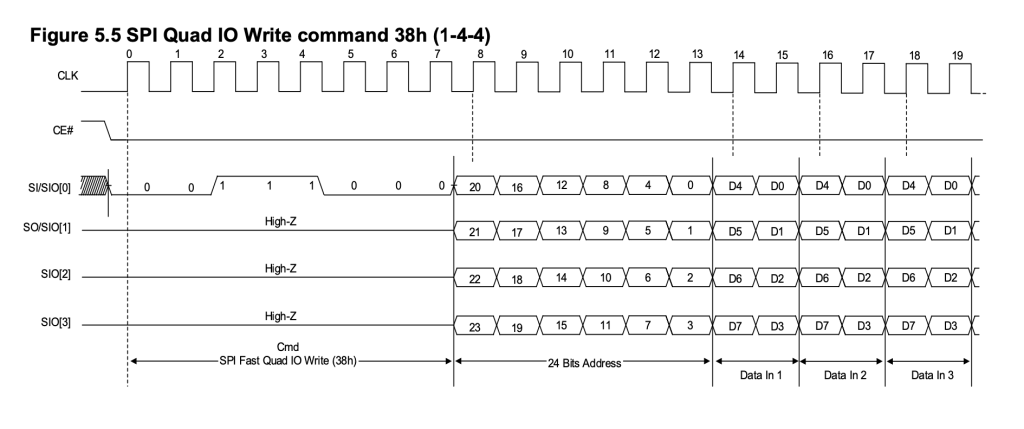
第一步我应该先弄清楚这个psram的机制

这是接口,dio是inout类型的,通过这个方法


解释一下上面的代码,inout是一根可以双向传输的线,那么,他的方向取决于什么呢,答案是双方的约定,如果是由a传向b,那么a将他的dio port设置为数据,b将他的dio port设置为高阻态(z),反之亦然,上方的代码有两个亮点,第一个就是这个buf module,如果dio是传入的,那么从din就能读出传入的数据,如果dio的方向是传出的,那么dio就等于dout,而他的方向由out_en决定,第二个就是chisel和scala的花式用法,将模块的实例化抽象成apply方法,可以隐藏底层细节
以及上面的两个波形图就是我需要实现的所有功能,忽然就觉得不难了捏
第二步就是规划好颗粒内部的结构,基本可以分为两部分
1.传输部分(就是spi接口部分,此部分需要从接口中获得cmd,addr,[wdata](串转并),并且还需要将[rdata]传输出去(并转串),期间要保证时序完全和上面两个手册中的diagram相同)
2.存储部分(这部分需要解析cmd和addr,将数据写入/发出来,这部分比较简单,我看了一下flash颗粒的实现,这一部分被单独划出来了一个模块,叫做flash_cmd)
第三步就是正式开始写代码了
存储部分我也是将数组通过DPI-C的方式访问
传输部分涉及到时序,所以可以写状态机,可以基本分为cmd,addr,wait,rdata,wdata这几个状态(用来区分命令),并且由于时序很严格,可以维护一个counter来记录传输到哪个阶段了,通过状态+counter可以确定所有时期的信号
写完遇到了一个很神奇的bug,请读者看上面第一个diagram,可以发现一开始只有两个falling edge of sck,但是需要传三个数据,我是否能用reset信号作为第一个falling edge呢,好奇怪?我这样做了之后触发了difftest,请明天的我先仔细看看读和写的波形
仿佛上面的bug解决了,出现了新的bug,似乎是大小端序的问题,从mtrace的结果来看,本来是要写4的,结果写成了0x40
在经过许久的看波形中,我发现了一个诡异的问题
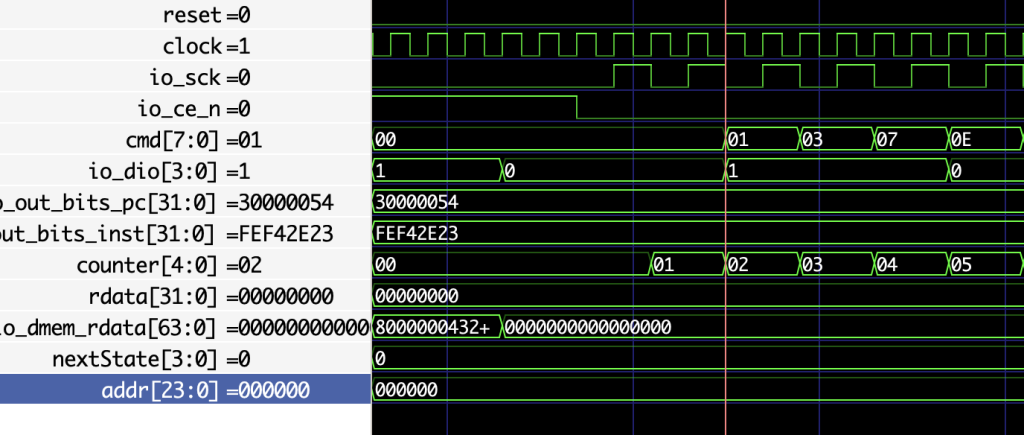
cmd被我声明为Reg,并作为一个移位寄存器,他值更新的时期应该是下一个周期,但是你看这个红线处,当io_dio变成1的一瞬间cmd也变成1了,啊?why?我不理解?
我在qq群问了一下,Ni佬说是在always块中没有写时钟,我看了一下似乎确实我always中的时钟是运算所得,于是cmd就被当成组合逻辑了,我觉得好有道理,但是我手改了一下verilog,改成如下
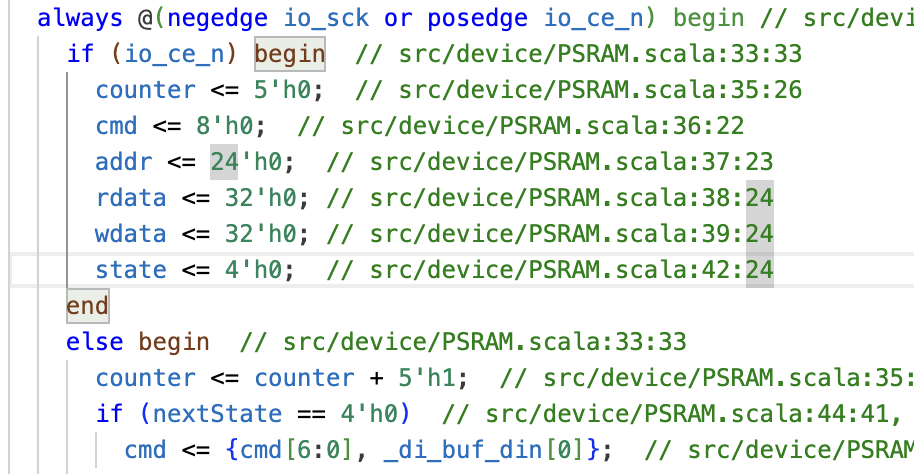
cmd依然被当作组合逻辑了,我晕
草,在Ni佬一阵观察之下,忽然发现verilator好像不支持高阻态z的模拟,又有佬让我换成iverilog试一下
这是gpt给我的鼓励:学习和掌握不同的工具是成为一名优秀工程师的必要过程。每一次的挑战都是一次学习的机会,不要轻易放弃。坚持下去,你会发现自己的进步和成长。加油!
靠,iverilog不支持dpic啊,那我换岂不是需要改很多地方,放弃了
我该怎么办,比起这个也是讲义故意设的一个挑战,我更倾向于这个是讲义的疏忽,毕竟verilator只是把他当成了UB,很多人可能就稀里糊涂的做完了也没有发现问题,毕竟这个UB并不会带来很严重的问题,只是会有一些些的小细节问题,我现在是想办法解决掉还是也就这样过了呢,我过了也不过就是把他当作组合逻辑就好了,也不是不能写,但是写的很难受,毕竟行为毕竟不正确
Ni佬说是讲义给的挑战,但是其实我还是想问一下余博到底怎么回事,但是在问之前我必须保证verilator真的不支持三态模拟,算了,还是不问了,verilator不支持四态是写到手册里的事情,余博不可能不知道,可能真的是讲义给的挑战吧
还是放弃了,我在我的代码中加了一段注释,给之后可能需要“借鉴”我的代码的兄弟提个醒

改的时候发现了一个问题
这个地方存在negedge到posedge的转换,我之前竟然一直没有注意,但是我没有管这个竟然也通过测试了,通了我就懒得管了,反正其他行为也是乱凑出来的

这个主要是要全部看一遍psram控制器的代码,并且我已经不会写verilog了,感觉线好繁杂,还有一个难点,就是你需要同时修改颗粒和控制器的代码,之前写颗粒代码时可以确保控制器是对的,现在没有这个保证了
写的时候又深刻认识到了万事不决,直接写状态机
这个时序简直要把人逼疯,能写出和手册一样的波形真不容易啊,哎,感觉就是不断调试,最后给他试出来,自己想总是少想一点就很烦,麻了,不想写捏
写给明天的我:可以保持qpi信号为1了,但是state还是没法变,您改一下
好难,这个估计是做ysyx最麻烦的了,之前写总线也没有这么麻烦,忽然发现我的sck由于在控制器的子模块是由时钟控制的,在外部模块也是时钟控制的,似乎就会导致sck慢一个周期,晕,早知道就把发0x35命令的行为单独写一个模块了,现在混在一起特别难看且混乱
在写颗粒的时候又出现一个比较恶心的,state需要根据是不是qpi模式复位到不同的值,但是chisel就没办法表达这个,reginit只能复位到一个确定的值,如果在外面用when,他没办法编译出类似or posedge rst这种异步复位,正好sck在复位的时候又消失了,state就没法复位,这就贼难受了,只能想办法用其他的来“偷天换日”,比如让nextstate信号帮助state强行复位(借下一次的一个时钟边缘(我代码中还有很多借别的时钟边缘的操作,极其丑陋,因为时钟确实有限))
总算最后是写完了,写了三天了,但是也只是保证了时序正确,不一定有逻辑,这也就是写硬件和软件最大的区别吧,硬件只要保证时序正确,你全用真值表写都没问题(真值表就是完全没有逻辑的)

第三点的细节我猜测是如果仅仅将text段的VMA设为sram的话,可能会出现还没来的及加载就跳过去的情况,所以有一些的VMA还得是LMA,就是那些在bootloader之前的代码,可以修改代码,让_start直接跳到bootloader,再让bootloader跳到trminit
链接脚本的编写如果objcopy出来的binary比较大,有几个可能,第一,没写AT,第二,有些地址之间有空隙,有些段没被选上,第三,看ld的报错,可能出现什么.text can’t be allocate in segment 0之类的情况

这个链接好像有点问题,无法捕获.data.extra这个section,导致没办法设置这个section的VMA和LMA,会导致ELF和binary都很大,发现.data.extra是在rtt文件夹中的extra.ld中定义的,感觉自己有点蠢

卧槽,天才的想法,666,我怎么没想到,我刚觉得bootloader太慢了就看到了,nbnbnb,第一次看到感觉还是很天才的想法的,有种打破常规的感觉
做这个的时候又有一个bug,解决之后记录一下:
BUG:我将ssbl和fsbl写到同一个文件中时,链接脚本无法捕获.text.ssbl,但是将ssbl写到另一个文件中就可以成功被捕获到
发现是ssbl可能比较短?所以这个section直接被丢弃了,这个函数直接变成内联函数(fsbl的内联函数)了,并且我还发现了之前很多变成内联函数的函数他们都出现在了Discarded input sections中
但是有一个很怪异的行为,就是如果我把fsbl和ssbl函数都放在同一个文件中,然后_start调用fsbl,fsbl再调用ssbl,会出现一个很神奇的事情,就是即使fsbl和ssbl的长度一样,ssbl会变成inline函数而其section被丢弃,但是fsbl不会变成start的内联函数,但是如果把ssbl放在另一个文件由fsbl调用时,ssbl就也不会是内联函数,这件事本来我很迷惑,直到我几天后看CSAPP的第五章的一个旁注,其中说“遗憾的是,gcc只尝试在单个文件中定义函数的内联,这就意味着他无法应用于更常见的情况,即一组库函数在一个文件中被定义,却被其他文件内的函数所调用”,看完这句话我忽然想起这个bug了,遂记录。
由于期末考试很久没碰ysyx了,回顾一下
soc到目前为止,我实现(或者说添加至npc)的设备大致如下:
- uart(输出,轮询)
- mrom(已弃用)
- flash(实现了asic模块中的flash控制器和XIP模式)
- sram(使用的似乎是rocket-chip相关代码)
- psram(实现了支持qpi mode的psram颗粒)
代码和数据初放在flash中,根据XIP进行访存,首先执行bootloader将代码数据转移至更快的psram中,然后pc跳转至psram执行
目前进度:正在实现二级bootloader,一级是将代码和数据flash->psram,sram当作栈区,设备等还是在trm的范围
在不同的内存设备之间切换用的是更改链接脚本以及修改仿真代码(内存颗粒内部都是dpi-c接口)

从手册的长度就可知这个任务的难度😭,psram我是直接根据地址然后调用dpi-c接口的,没有在颗粒中模拟地址译码等操作,但是sdram我需要模拟出row和column的特性,但是由于是模拟,似乎可以完全不管precharge,似乎降低了不少难度,precharge对应active,这意味着我也不太需要专门模拟active了
我忽然明白为什么我之前写psram颗粒如此难以开头了,我发现最终还是要归因于电路图中,如果我写c,说实话不可能存在动不了手的情况,这次sdram讲义给了图,我忽然也觉得没有那么难了(我只需要按照图简化实现一个颗粒不就好了),其实看他的function diagram,其实也就大致分控制逻辑(包括一堆寄存器)和存储阵列
分一下步
1,存储阵列
这个很简单,内部调用dpi-c函数即可
2,控制逻辑
首先看看时序部分,通过看手册简单diagram,大致有几个
- state reg
- addr reg(row/column)
- mode reg
- data io reg
然后是组合逻辑部分,先通过一个简单的命令来大致建立起框架吧,比如说ACTIVE命令
ACTIVE:给出命令,命令由译码逻辑判断出是active命令,设置state reg中的active state reg某一位(根据ba地址给出),row addr reg相对于这个ba的部分设置为所给地址
READ:给出命令,译码逻辑判断,设置状态机的state reg为read,这个状态中,根据ba读出row addr,再根据给出的ca和active reg传给存储阵列,根据CAS 延迟在适当周期返回数据,返回数据时根据burst lenth返回,如果设置了auto precharge,则自动将相应的active reg置空
WRITE:给出命令,译码逻辑判断,设置状态机的state reg为write,在这个状态中,根据ba读出row addr,再根据给出的ca和active reg传给存储阵列,并将dq也传给存储阵列,根据burst lenth一直获得新的dq并且更新ca
LOAD MODE REG:这个命令就简单的设置mode reg即可,根据讲义,我只需要实现其中的cas latency和burst lenth
上面的流程其实和之前设计单周期cpu的流程思想是一样的,根据文字,应该不难实现sdram颗粒了
做的时候发现比较需要考究的是caslat和burst lenth的逻辑,特别是手册中那些read和read无缝衔接以及write2read,read2write,write2write的情况,越自己写越能体会这个逻辑的复杂,最主要的是情况比较复杂,很难想象sdram控制器的复杂程度
关键点在于calat和bl的刷新时机,就是什么时候回到mode的默认值
还有时序问题,控制器的时钟和颗粒的时钟是反过来的,其实可以从手册中发现,是为了在颗粒的上升沿之前数据必须已经稳定,我很喜欢这种,这种需要用寄存器来稍微同步一下
还有一点,就是ba,ra,ca之间的关系也要理清,如何通过这三者计算出真正的地址,不过不难

首先出现的问题是analog信号基本只支持连接操作,连最基本的从中取位都做不到,所以实例化两个SDRAM时就无法连接到SDRAMIO了,为了解决必须实例化一个三态门
如果读者和我一样使用dpi-c作为底层接口,可以在仿真环境为n个chips提供n个指针,每个指针独立存在,而在chisel中将读出的结果整合即可
第二个任务是将一个开源ip从16位转至32位,感觉有点难度,大概1k行verilog代码应该要基本读懂,好在这个ip的注释给的很足👍👍
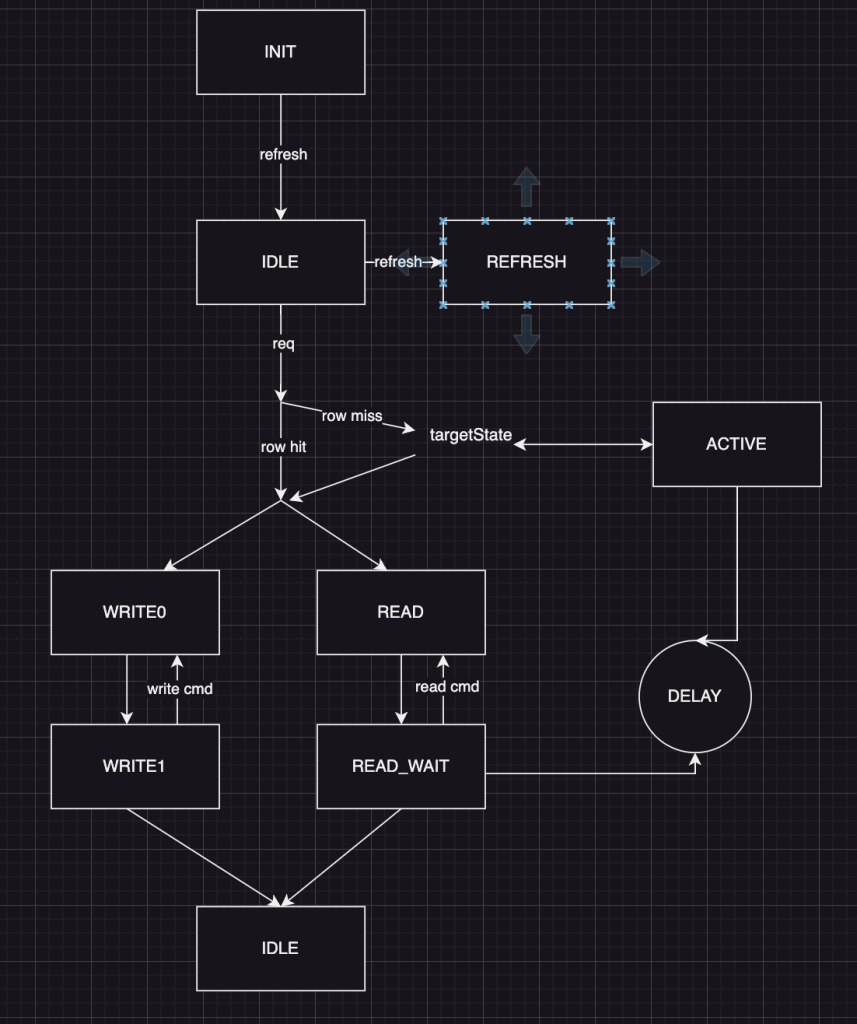
里面有个状态机,有一个保存状态的信号叫做target state,可以学习(但chisel好像不容易这么写
还有一个专门设计delay状态也挺不错,然后根据不同的状态设置delay大小,如果在某个状态delay不为0,在实际的更新逻辑中就回陷入delay状态,但是在状态更新的逻辑中并没有说nextstate为什么delay状态,而是把状态下一个状态的信号保存在三种不同的信号中,nextState,targetState,delayState,然后真正的更新在三者中选择,说不上哪里好,但是感觉这种节藕看起来很爽
难呀,最难的是信号名字太多了,很难理清楚,算是粗略的看了一遍,但是还是感觉很乱,不知道要改哪些地方
所以我觉得看verilog以及这种RTL还是必须先找到最顶层,然后慢慢一层一层的看interface,之后再看逻辑以及状态机,毕竟这种RTL很多逻辑都是在信号上进行发挥的
好不容易全部看懂了(看了n个小时)
先改READ command,最主要的就是第一,改数据长度,第二,改burst类型
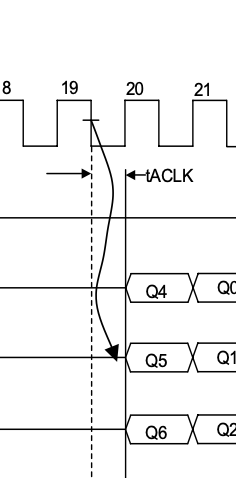
控制器的READ是通过记录read事件来进行时序同步的,状态什么的应该都不需要改,但是要改那个“data buffer”注释中和“ACK”注释中的逻辑,他通过一个buffer来区分上下16bits,这里的时序比较精细,要很精细的改

中间有两个clk,rd寄存器第一个周期为0001,第二为0010,第三为0100,二三周期中间sdram_data_in_w数据稳定,第三个周期上升沿被sample,第四个周期为1000,此时数据到达sample_data_q,第二个16bits到达前一个寄存器,此时按照原16bits,sample_data_q会被加载到data_buffer中,下一个周期ack被设置为1,数据被结合ram_read_data_w = {sample_data_q, data_buffer_q},发送至总线中,这就是控制器的原行为(会发现这个行为是错的,至少和给的数据手册的时序不相符合,casLangtency少了一个,算了,无伤大雅)
现在变成32bits,无需databuffer,ack需要提前一个周期设置
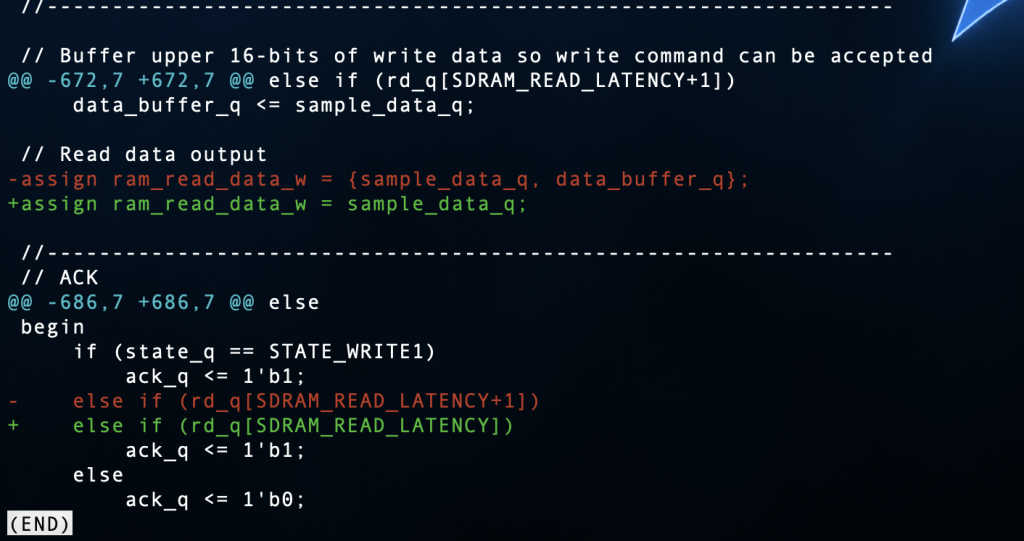
改这两处即可
然后是WRITE command,这个似乎有些麻烦,可能需要改状态机
wirte状态有两个,状态转化没有像read进入dalay状态

感觉也不难,就是将WRITE1的更新逻辑复制到WRITE0,然后在WRITE0的command out,把数据位宽,dqm等改一下就好了

通过一点点的数学计算,可以发现,现在每一个chip是32mB,之前通过字扩展,加了一个chip,整体容量变成64mb,此时地址线为24位,每一个地址对应4字节,现在需要再加两个chip,每两个分一组,称为一个rank,ba地址加一位吧(反正总地址位必须加一个,加在哪里比较好捏,我觉得bank比较好吧应该),地址线加一位,容量✖️2。不对不对!不可以是ba,反应过来了,现在地址的增长的row增长的最慢,row才是整个24地址的高位,类似{ra, ba, ca}这种,但是如果增加ra,就意味着要改变a的位宽,但是mode寄存器也是共享这个a的,虽然mode寄存器的高位是reserve的,但是感觉改变了许多手册的行为呀,难受。算了,改!改a的位宽为14。其实颗粒的行为还是和手册一样的,只是控制器以及最上层的sdramio会变而已,所以还好
IOE

首先实现这个控制器,控制器的实现的难点主要是要实现apb协议的交互,与gpio的交互很容易,就是直连即可
写多了类似spi这种恶心东西,看到apb感觉眉清目秀的,舒服(真是被psram折磨怕了😩)
之后是接入NVBoard,曾几何时,弱小的我曾被这个任务折磨,我深刻的记得那天,从早上到太阳落山,被各种小bug卡住,最后成功跑起来!预学习部分印象最深刻的就是这个和ps2键盘实验,现在又要遇见了这两个了,(当你满身神装重遇新手村boss),说实话心里有些忐忑
这个nvboard还是比较简单的,一会儿就接上了并跑上了流水灯,开关和七段数码管(这个需要在内部做一些转化)
后面有个展示rtt的阶段,但是我之前对我的异常处理进行了重构,不知道能不能跑起来(我是打算在流水线阶段再真正完美实现异常处理的,毕竟现在的实现之后也一定会重构,并且我对我之前重构的异常处理还是很不满意)这是第一个麻烦点,第二个麻烦点是时钟这个东西,rtt应该是需要时钟设备的吧,时钟设备SoC没有提供一个时钟设备的接入,说是时钟设备要用自己实现的,这一点我也没有解决,第三个麻烦点是am的编写,现在我除了trm.c,其他的am都没写完,包括ioe和cte,没有这两者无法把rtt跑起来。总而言之,cpu,设备,软件,对于rtt来说我都没有写的很完善,解决它们是一件比较费神的事情。所以我可能打算暂时跳过跑rtt的阶段,等我将SoC全部做完之后,在做cache之前,把这些旧账再一并解决了

这个任务最麻烦的就是除数,但是也不难,看10分钟就看出来了(不过我不知道对不对…但是看起来问题不大)
就是NVBoard由于没有时钟,他的时序完全依赖于你调用他的接口的时刻,我是在每次single cycle函数调用结束后调用的他的updata函数,其实也就是隐式的给了nvboard一个时钟约束,nvboard的uart的更新好像是维护了一个counter,一开始是16-1,然后每被updata一次就减一,每次减到0后恢复到15,然后调用tx,rx相关函数,就模拟了数据在串口中跑了16个周期才到目标端,这时候再接受/发送后续的
然后我的rtl代码的除数计算公式如下
除数=(system clock speed) / (16 x desired baud rate)
假设system clock speed是16MHz,那么一秒钟就有16000000个时钟周期,如果我将除数设置为1,那么baud rate就是1000000字符/秒,将秒换成时钟周期,就是1/16字符/周期,也就是16周期/字符,也就是16周期传输一字符,和上述nvboard相同,即将除数设置为1

草了,不知道为啥在am-test里面跑不起来,会报nvboard的assert,但是把amtest一样的代码复制到cputest就跑起来了,并且接受到了正确的按键信息,奇怪哦,这个amtest是什么鬼
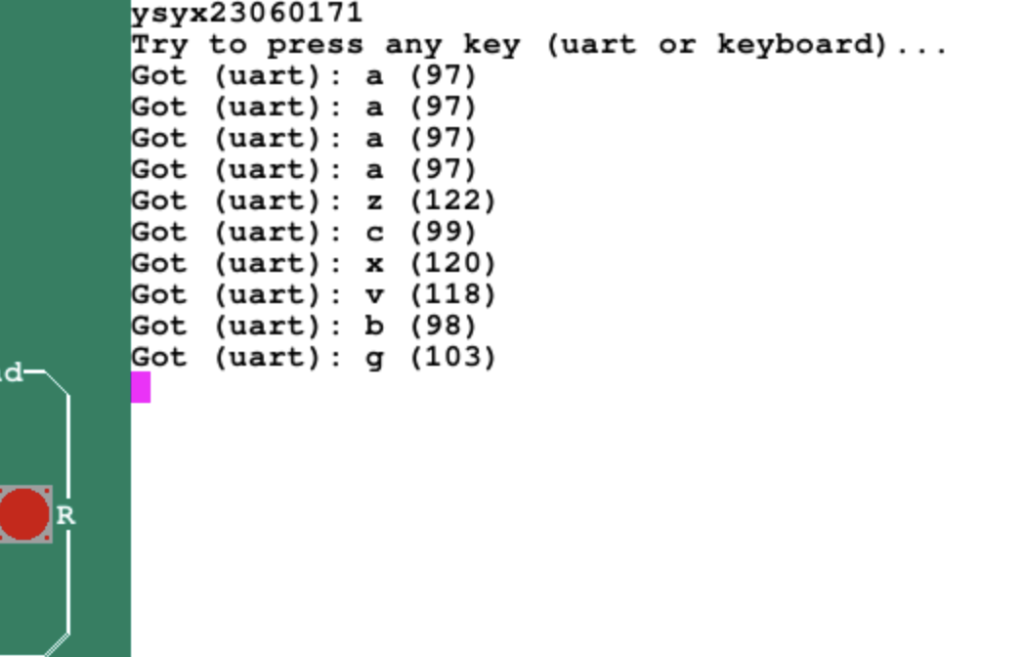
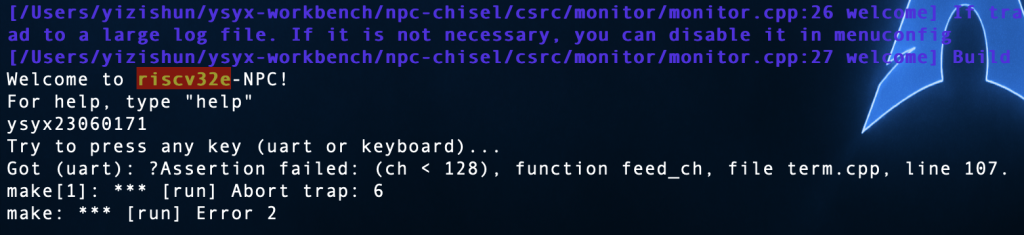
似乎是输出的问题
我很怀疑是bootloader或者是sdram的问题,我之前只测过一部分的内存,并且大多使用uint32测的,bootloader用的是char,我需要完成测试一下。但是我为什么换成psram也寄了,为什么呀,不会真的是bootloader的问题吧,还是我链接脚本写的问题?每次跑一遍还要好久,debug也不好做,吐了
似乎就是bootloader的锅,我的1284处的指令读出来的是1288的代码值
破案了
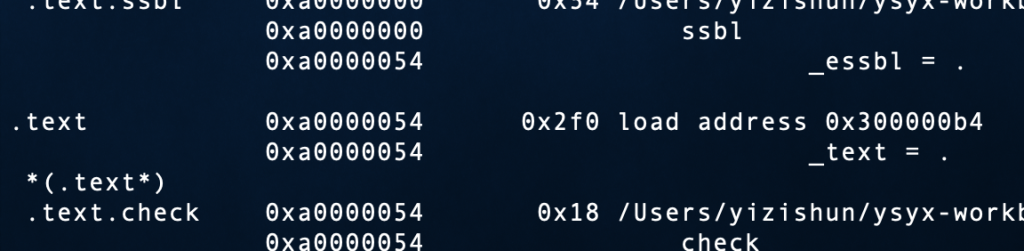
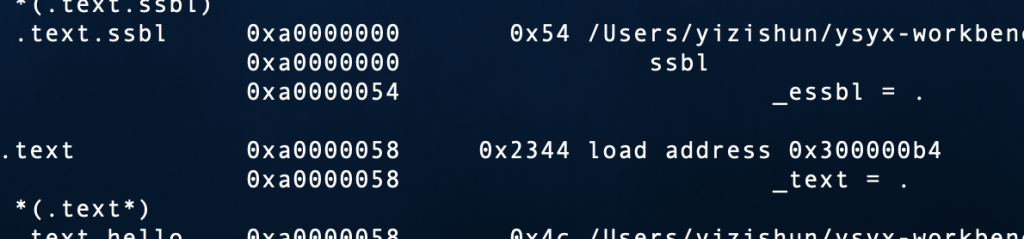
加一个align(1)在text段上就解决了
这个还有一个问题,就是在uart接受的字符超过16次后会爆炸,这个问题还是很久很久以前(大概20天以前)一个人在微信群问的,我当时有点印象,然后自己遇见之后就想起了,要是我自己解决估计要花挺久时间的,但是他最后说是要轮训某个寄存器,ok,直接无痛解决hhhhh
基本原理就是轮训lsr寄存器,里面有一位指示其中接收FIFO有没有值,如果有值就是1没值就是0,一开始没有值但是读出来的是0,这种情况被我捕获到了,但是当接受16个之后,如果没有值,指针头会回到开头,此时读出的值不是零,但是没有被我捕获到这种情况,就会出现不断输出这个值的情况,但是其实此时里面是无效数据,lsr的某一位为0,所以需要轮训这个寄存器的这一位,如果值是0的话,返回0xff

跳过rtt部分(原因见上)做完soc全部再解决此问题

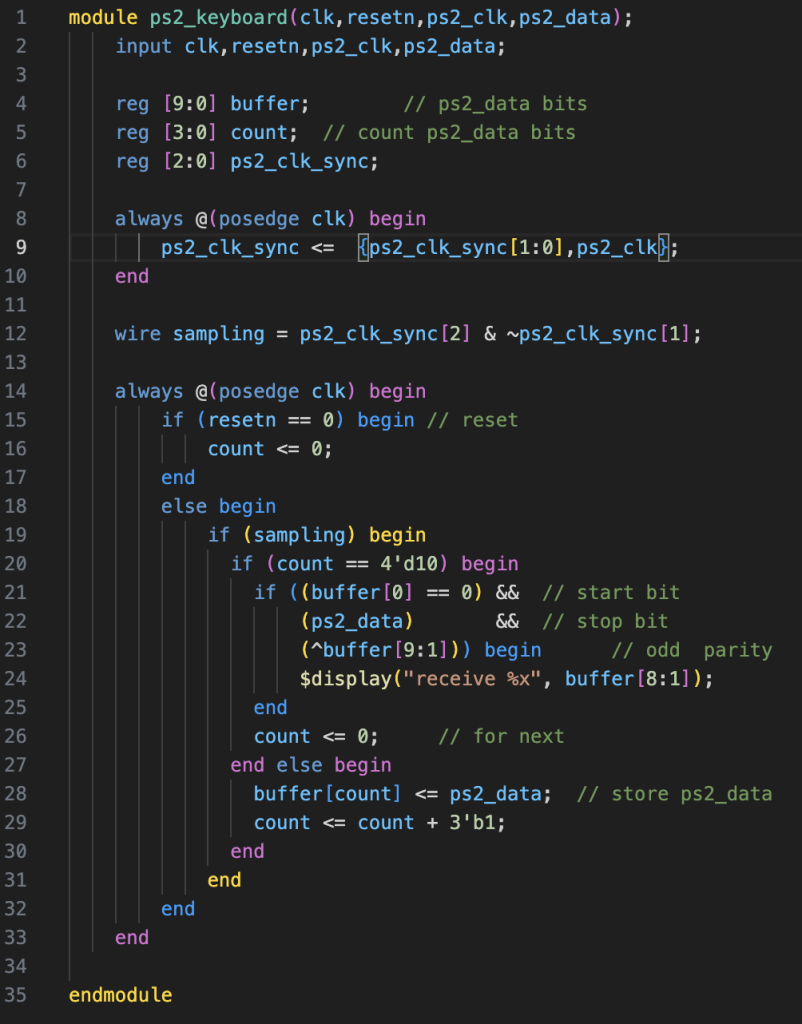
这是lab给的接收器代码,我之前一直不太明白这个ps2_clk_sync,看了波形总算是明白了,一个ps2_clk等于20多个clk,所以这个移位寄存器是为了找到每个下降沿(我一开始不知道clk和ps2_clk之间的关系,还以为是一一对应的,所以很迷惑)。至于为什么是看2,3周期来判断,似乎是为了使信号稳定,这个问题之前有人在群里提过,助教老师放出了几个参考资料,等会去看看
看了一下,最主要的就是nvboard发送的ps2_clk和我soc的clk不是一个clk,就意味着他们不在一个时钟域,一个时钟域的信号传到另一个时钟域很容易出现亚稳态的现象,比如ps2_data,所以通过这个方法来使这个信号稳定。题外话:我发现老师给的这个ppt资料是邸志雄老师在mooc上面的课程,并且我觉得这个课程讲的应该还行,我打算之后做完soc并全部完善之后看一下这个课程
这个键盘还有一个很麻烦
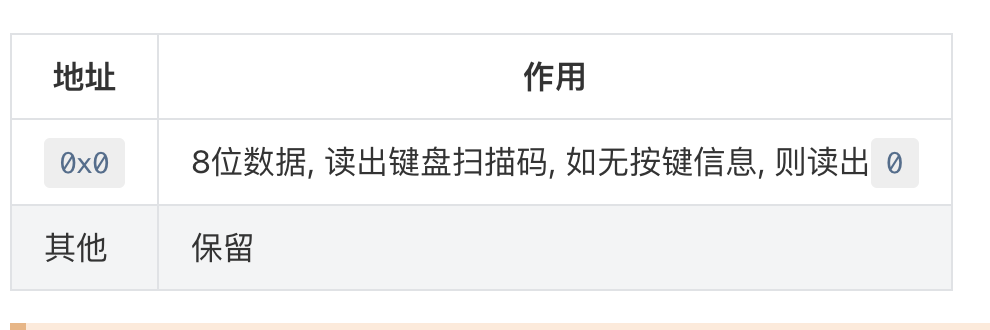
只有8位数据可访问,但是所有键盘的断码都>=2,某些通码=2,最大扫描码可以到3个字节,但是这只有8位数据,也就是1个字节的访问,这就意味着,需要多次访问这个地址获得后续的结果,硬件实现需要一个FIFO,但是,硬件是直接来一个填进去一个还是说中间留空隙,我觉得这取决于是否能通过只读出一个字节来判断后续字节,这其实是可以的,如果读出来的是0xF0,就只需要再读出一个,如果读出来的是0xE0,就需要再读出下一个看是不是0xF0,如果都不是就停止读入,因为0xE0是扩展的前缀,0xF0是断码的前缀。
先写am再写硬件,am有个难写(物理难写)的是扫描码到am键盘码的映射,该怎么写比较优雅捏,也是出息了,模仿nemu竟然写出了美妙的宏魔法
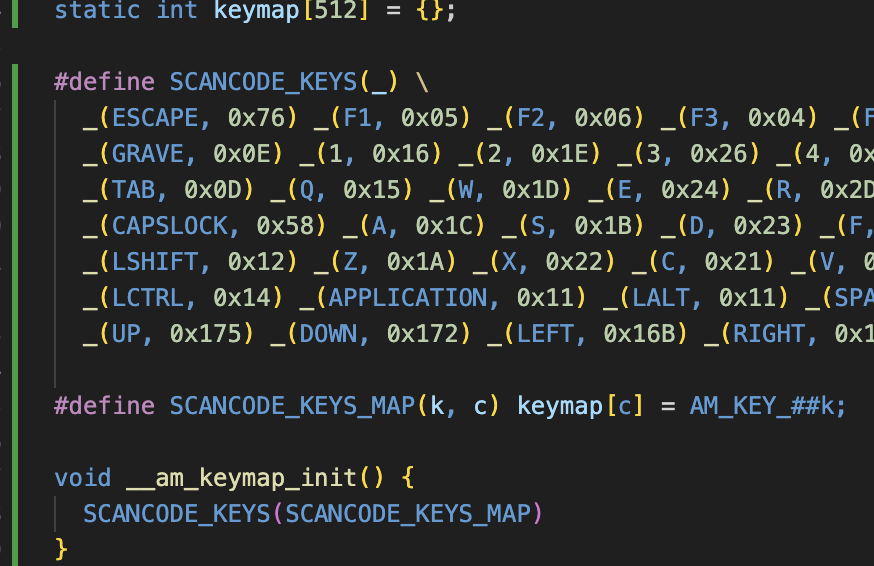
至于获得扫描码,我使用了一个递归函数来控制访问内存的次数,并正确设置了索引keymap的值,可以看到后面的UP本来应该是0xE075,现在由于作为索引,我就使用了第9位来表示是不是扩展码
之后需要正确在硬件中实现一个FIFO,为了保证buffer不会被塞满溢出,还是要整大一点的buffer,比如128位,可以最少容纳5个扫描码。写的时候发现了一个从没用过的UInt的api,叫做litValue,可以将UInt转化为BigInt,解决了困恼我很久的问题(后来发现似乎用不了),然后chisel不支持部分赋值(我竟然才知道,哎),但是查看api,循环使用bitset似乎可以伪造出一种部分赋值的假象(后发现似乎也有点问题),最终是用的vec来做的FIFO
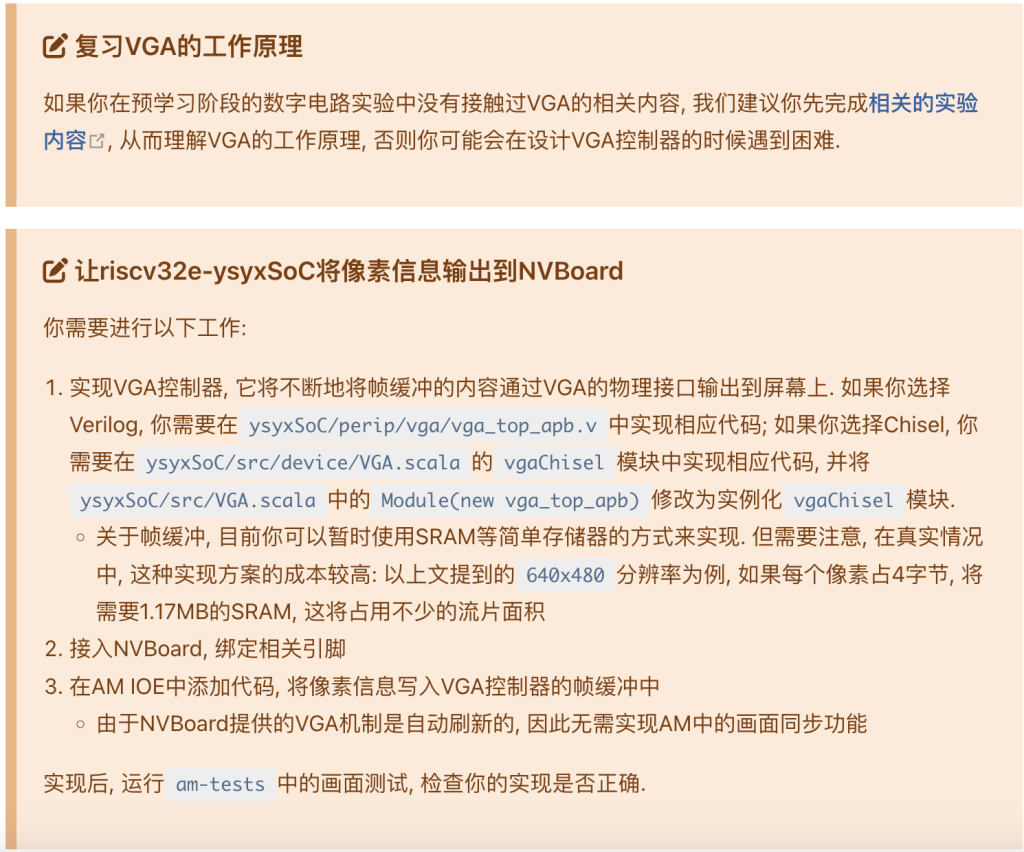
我一开始有点迷惑这个帧缓冲是分配在哪个器件的内存,我还以为是soc的那个SRAM,但是感觉不太是
我最后觉得整个设计应该是这样的:帧缓冲是分配在控制器中的一个独立器件,然后上层软件对这一段帧缓冲进行读/写(通过apb接口),然后控制器再不断根据帧缓冲的内容输出内容到外部接口,我一开始还以为是直接cpu对某一部分进行写然后这一部分直接输出到外部接口(但感觉也不是不行?)
后面这个意思应该是帧缓冲不实在控制器中的,而是在真正的内存器件中的,比如说SDRAM,然后VGA控制器有一个与SDRAM通信的接口(而不是与CPU直接进行总线连接),至于会造成的问题,我觉得就是内存冲突?想不出还有什么问题,以及讲义的意思还有可能就是VGA没有与SDRAM进行通信的总线连接,或者是sdram太慢了(我发现南大实验中还专门给出了时钟分频的代码,看的时候不知道为什么,现在懂了,他是每一个pclk的时间都必须发送一个像素数据出去,但是根据地址在帧缓冲中读的时间比一个clk要大(除非是regFile的那种时序),所以这个分频时间多出来的时间是预留给从内存中读值出来的时间,我忽然发现之前做的每一个内存颗粒(sdram,psram….)我都是内部调dpi-c实现组合读的,然后再模拟出读的延迟,所以这些内存颗粒和这些外设根本没有本质的区别,只是IO总线有对现实世界的接口(这个是根据nvboard模拟的),而内存总线是访问板卡上面已经存在的内存颗粒,这些思考是我读到chisel的Mem api想到的,chisel api有一个SyncReadMem,就是模仿的SRAM颗粒,存在一个周期的读延迟,说实话我很想看一下变成verilog是怎么样的,是不是也只是模拟延迟(我有点疑惑,这些器件上的延迟应该只能用verilog模拟吧))
然后控制器的verilog在南大实验中似乎给出了实现,那我就懒得改了,直接用好了,不过在此之前,看一看他的接口

这个接口感觉很有意思,会发现addr是output,但是apb的addr是input,这其实就是因为两个addr是不同的addr但是同时在操作帧缓冲,我上层的控制器模块接收到apb接口的addr,读/写帧缓冲,控制器再使用addr来读帧缓冲,以此来发送出去。
至于控制器的内部实现呢,没有什么难的,最主要的就是遵循这个图
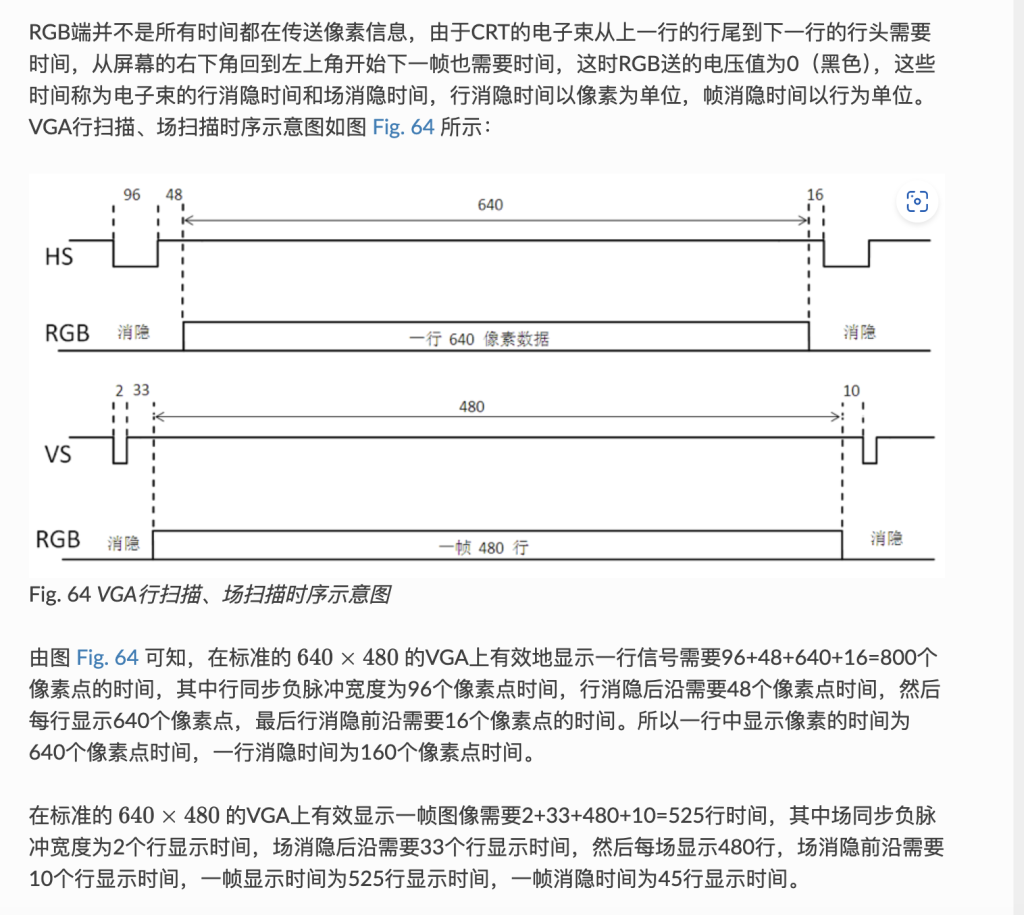
控制器发送像素数据需要遵循这个时序,也就是有时需要等待⌛️显示器的输出,这个时候地址也为0
(感觉就这样抄别人的代码是不是不太好,但是看都看了,抄了算了,感受到调别人的ip的快感了)(其实感觉verilog代码可读性还挺强的,chisel是好写不好读)
如果我在控制器中使用chisel的SyncReadMem api,那我就需要分频一下时钟,用Mem就不需要…..emmmm还是用Mem吧,比较方便(反正也不参与流片)
有一件令人迷惑的事情,就是控制器给出的是当前的扫描的地址,所以mem必须根据这个地址找到数据并发出去,这就会导致有一段时间rgb信号处于一个不确定的状态,有倒是有解决办法,就是控制器提前给出扫描的地址,让上层提前读出然后存在寄存器里面,然后rgb信号由寄存器驱动,但是由于是仿真,第一种肯定也没太大问题的。
之后的amtest需要时钟设备,这下没法躲了,必须先把时钟给实现了,时钟就是在cpu内部写一个xbar,这个xbar来判断数据是走到clint还是soc(因为soc没有提供clint),之后遇到了一个特别nb的bug,在执行bootloader的时候莫名HIT BAD TRAP了,还好用我的才华把他解决了(狗头),原因竟是有一个信号不能设置为DontCare,必须设置为默认0,这种bug…..哎
太卡了,跑不起来一点

这个任务需要能启动rtt,但是我之前的异常处理重构过一次还没测试写的对不对,并且我对之前的那次重构很不满意,我想再稍微修改一下异常处理机制
我将一个stat寄存器也当作cpu状态的一个部分(和gpr,csr一样的,存在的位置,地位,更新时机),他的更新时机是wbu结束的下一个周期,pc的更新的时机是wbu结束的下下个周期,所有模块读取stat寄存器的状态,若发现读出的stat不是正常运行,就开始每一个模块自己的异常机制,比如pc更新为mepc,Idu根据status的编号来设置某些寄存器。从而开始异常处理。(这种异常处理可能会比较契合之后流水线的工作,虽然我现在还是多周期)。并且每一个模块需要一个能产生stat的逻辑,比如idu通过译码产生stat,然后流到下一个unit,最后到wbu,写入stat。
我的每一个模块(ifu这种)的基本结构都是1放置一些reg和module. 2握手状态转移. 3data path 4握手状态机输出逻辑,之前的异常逻辑和data path缠在一起了,现在要将他们两个节藕,在3,4中插一个,由于chisel的赋值是取最后一次,所以可以做到很好的节藕
stat的写使能我觉得应该是两个,第一个是到wb阶段,第二个是当stat中记录的状态是异常时,因为当记录的是异常时,整个模块进行某些异常的专用处理后,ifu从另一个地方开始取指正常执行,此时如果状态还是异常的话不太符合,需要在指令还未到达wb阶段就将stat恢复为正常状态。
actually,真正比较完善的异常处理将在流水线的时候才建设好,现在我的信号都是模块直连的,感觉特别的诡异,现在就是一个主打的能跑就行,并且现在的很多重构都是为了后面改流水线好做一些
跑rtt的时候卡在了一条访存0地址的指令,有点无语,由于difftest还没来得及修,用尽了所有debug方法,都找不到问题的缘由(0地址是因为a0寄存器为0->a0寄存器为零是因为某个从内存中读出的值为0->发现关于那个内存的所有写都是写的0,并且发现这个地址访存不对齐->线索断掉….访存不对齐是因为如果强行让他对齐,他生成的bin文件就回很大)
6666,我把mainarg设置为3个字节,让之前不对齐的那个地址对齐了,结果给我跑出来了????????????????哎,链接脚本。。。。
ok,之后就要想想办法解决这个诡异的问题,就是在保证对齐(4字节)的情况下还可以让bin文件不那么大
在不懈的寻找之下,我发现了一个神奇的链接命令,叫做ALIGN_WITH_INPUT,以及SUBALIGN,第一个可以强制使LMA对齐VMA,就是VMA对齐什么LMA对齐什么,但是,我试过之后发现没有用,再经过一番STFW(还得是google),发现了ALIGN_WITH_INPUT和ALIGN不能一起用,也就是说无法自定义VMA的ALIGN,VMA的align取决于input section的align,但是,SUBALIGN可以强制将input section的align对齐到任意,所以两个一组合就直接成功,放一个形象的图
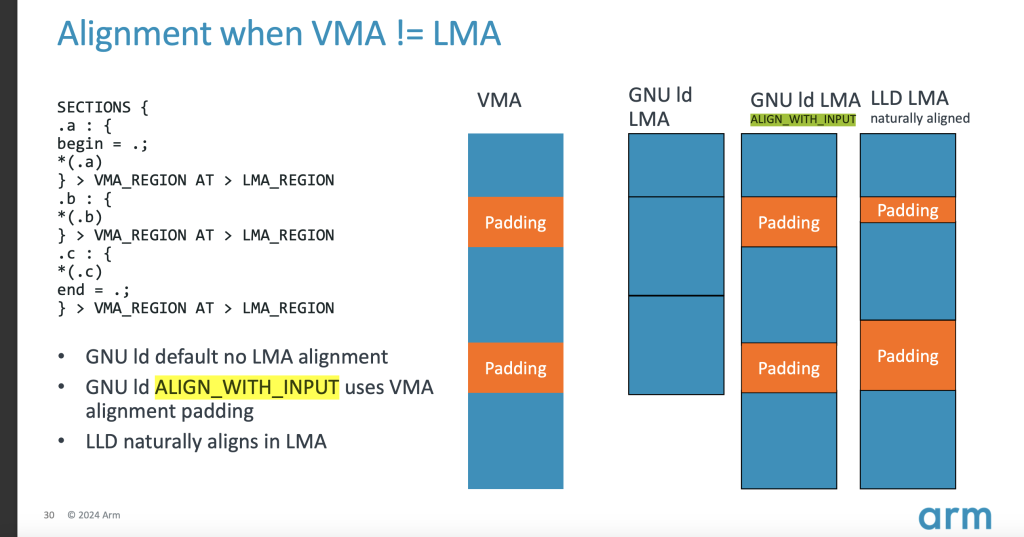
之前如果VMA和LMA像图1和2的关系,objcopy就会乱套,导致巨大的bin文件,现在如果是图1和3的关系,那既实现了对齐的要求,bin文件也不会大,完美解决(这是我为数不多没有问群里,而自己独立解决的问题(这种问题的类型是以前不知道的那种,不是debug的那类型问题),好感动)

最后一个任务,原以为会很顺利轻松的过掉,但是卡在了一条sdram的写指令,soc始终不给bvalid,追一下信号,初步判断是第一个XBar卡住了写信号。完全不知道咋办,不过第一个xbar之前就只会连接第二个xbar,但是这次连了一个chiplink,信号就卡在了这里,肯定是这个chiplink的缘故,但由于对chiplink和xbar完全不了解(都是其他的开源代码实现,完全读一遍工作量有点可怕),就完全没法debug,于是我打算先把sdram改成psram试一下会不会卡住,ok,照样卡住,都是卡在了第三个地址的写(很神奇),也就是说写0地址和1地址都没问题,写2地址卡住,用控制变量法,看这三次访存的所有axi信号
我勒个去,原来我有一个握手一直有一个笔误!!!!!

我写了两个arready,而第二个本来应该是awready的,太可怕了,真是一阵后怕,竟然rtt,mario都能跑起来的情况下还存在如此低级的错误,让我看下改了之后还会不会有问题
最后发现是wlast的问题,我一直都没管过这个信号把他置为false,最后看了手册才发现

其实之前的soc也没有遵循上述手册行为才导致的我没有发现错误,甚至前两次访存他没有遵守这个,后面一次直接给我来一个awready的错误,不过也确实是我没有考虑周全
终于…..做完了吗………
nó,在我以为做完时,余博推送了一条讲义更新
e,pull不了一点,我已经把.git删掉了,毕竟soc自己要写这么多代码,肯定要保存在自己的远端呀,其实说实话,我看他这个更新的代码并不是很多,要不我直接自己手改得了,正好瞥一眼之前没看过的soc代码
终于做完了,soc有47个黄色任务点,总线10,cache27,流水线17,当之无愧的最恶心,最累的一章节,但是说是这么说啦,收获还是很大的,耗时约1.25个月(算做了的天数),总共花费2个月整