
我是在做pa2.1的中间开始写这篇文章的,所以pa2.1可能写的比较简略,pa2的链接:https://nju-projectn.github.io/ics-pa-gitbook/ics2023/PA2.html。我使用的isa是riscv32(毕竟最简单hhh)。以下是正文
PA2.1
2.1的任务就主要是实现指令,众所周知,实现一条指令有四步:1.fetch 2.decode 3.execue 4.pc++,第一步和第四步很简单,最麻烦的是译码和执行,但译码的工作源码已经替我们完成了,源码的模式匹配使得我们之后写出的指令非常直观和美丽(话说里面的有一个函数我还没看懂(pattern_decode函数)TODO),之后我们需要做的便只是添加指令,这是我截至23/12/3实现的所有指令(这些指令全是我看全英文档实现的,不是我有多强,是我根本不知道还有中文文档555,之后我就会看中文文档了,中文链接:中文,英文链接:English)
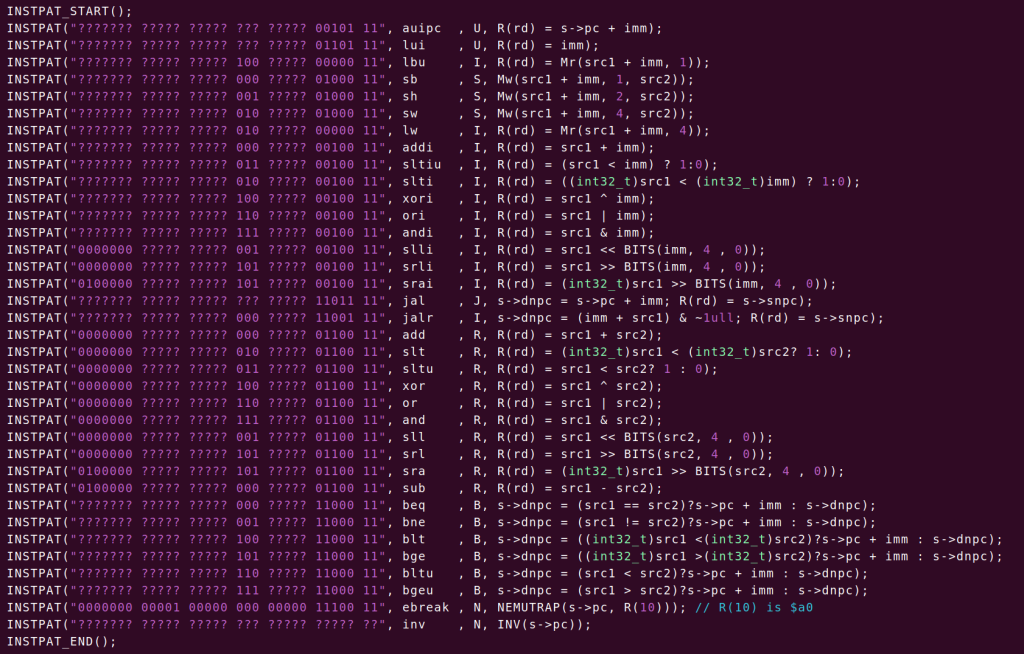
上述指令可以通过add,add-longlong,bit,crc32测试,但是在bubble-sort里面会陷入死循环,说明我的指令存在bug,我用pa1实现的命令想定位error,可是想在这么多指令中找出一个微小的错误实在不容易(一是因为找错还需要不断翻阅手册,而且tm还是全英,二是我没有什么特别工具能帮我找这种错误),于是在我不断寻找下,我发现之后的diff test任务就是为了找我这种错误的
Diff test

diff test首先使用init_difftest初始化,里面有几个库函数我第一次见到,dlopen,dlsym,dlclose,主要作用是打开动态链接库文件,void (*ref_difftest_init)(int) = dlsym(handle, "difftest_init");里面存在这一行代码,理应这种操作应该是ld.so做的,但是现在竟然使用代码实现了,感觉有点神奇且诡异,于是我去看了看dlsym的源码,然后发现完全看不懂555,但原理应该还是需要调用ld.so。好了,之后就是RTFSC+实现了,以下是我的实现(可能有bug,且写的很屎)
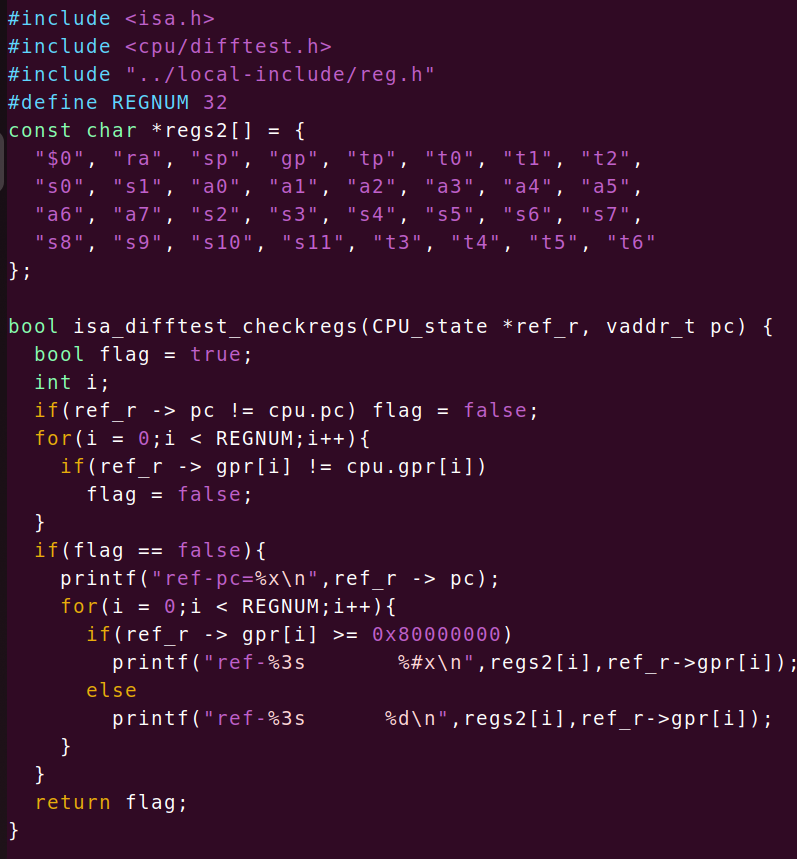
不得不说,这个diff test是真牛逼,当我怀着忐忑的心情再次运行bubble-sort,我终于发现了error,ref-pc=80000060,dut-pc=80000044,两个pc不同,于是再回去找fault,是bge指令实现错误,然后我发现bge是大于等于,ble是小于,(欲哭无泪),为啥是大于等于啊啊啊啊!然后我发现手册上真的写的是大于等于,只是我没看清(哎,我这粗心的毛病已经耽误了我高考了,我啥时候能改一下啊哎)BGE and BGEU take the branch if rs1 is greater than or equal to rs2,之后就HIT GOOD TRAP了,这个小插曲终于告一段落。
其实在程序设计课做pta或者oj的时候,示例输入输出就相当于ref,实际上我们一直在做diff test!
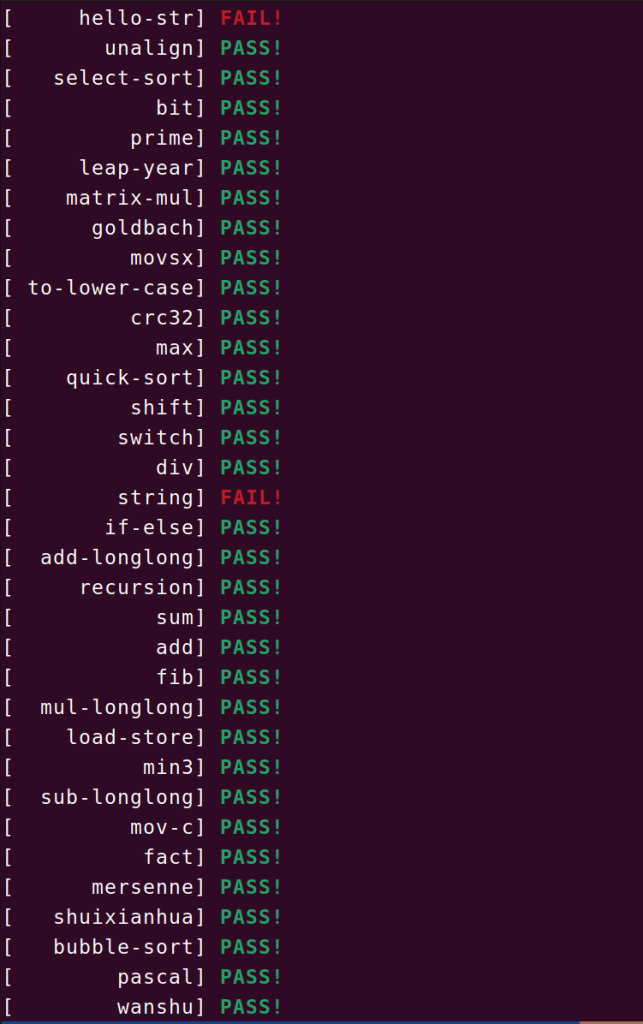
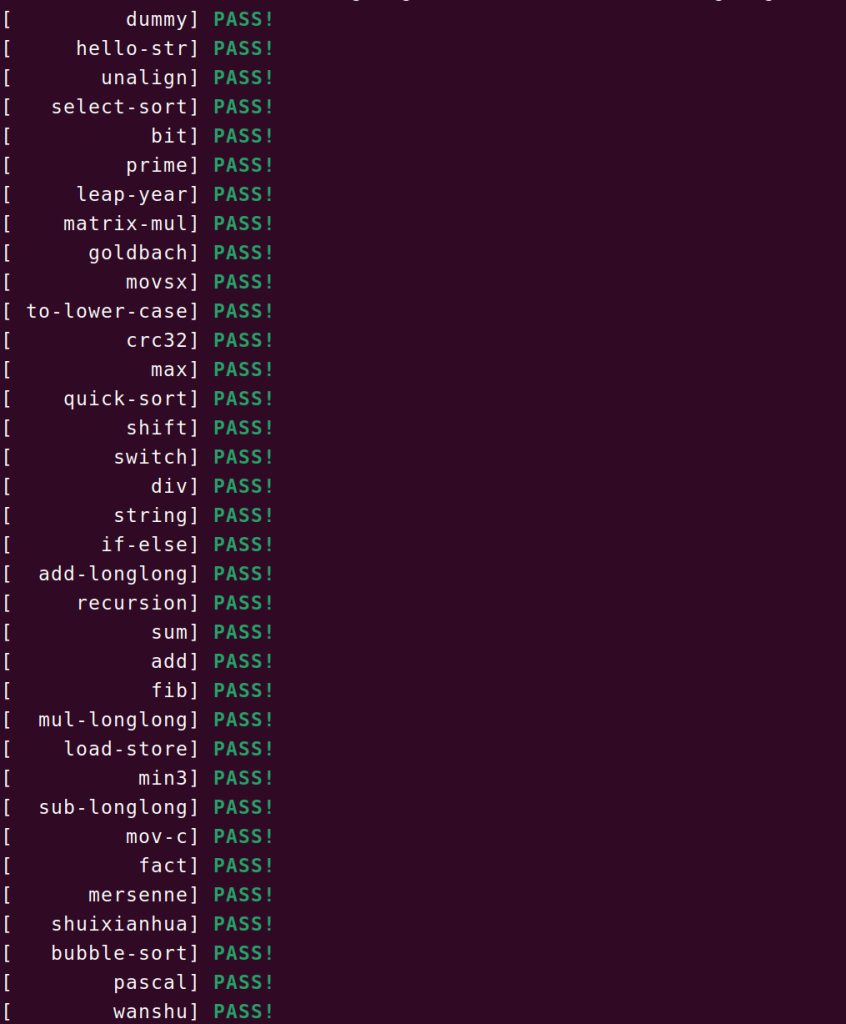
后面就是痛苦的一条一条指令去实现了,中文手册最后有十分便利的实现方法,极大加快了我的速度,我最后实现了44条指令,可以通过除了‘string’和’hello-str’的全部测试。

PA2.2
AM
abstract machine对我来说是一个全新的概念,我把整个编译过程看了一遍才隐约的懂一点点(所以说理解一个计算机概念的好方法就是直接看他的实现),具体来说,一个程序需要一个运行时环境,从现在来说,程序的运行时环境就特别简单(TRM),这个运行时环境帮助程序开辟了程序空间(stack heap)可供程序使用,并帮助程序退出。我们怎么去理解am呢,可以想象假设没有am,程序就只是一堆二进制,被nemu执行,pc首先指向main函数的第一个指令,似乎也可以全部执行成功哎。但是对比于有am的情况,程序被编译成存在运行时环境的二进制文件传给nemu,nemu指向_start节而不是main,这个节帮助开辟stack(对比而言上一个程序就连栈空间都没有),然后跳转到init_trm,在这个节调用main(这可以保证main函数可以返回到这个节中,对比而言上一个main函数就返回不了),并在init这个节中调用halt停止程序运行(对比而言,上一个程序就无法停止,pc会指向一个非法指令)
对于makefile呢,这整个项目有很多makefile,目前为止,有三个主makefile,分别存在于1./ics2023/nemu(编译运行nemu)2.am-kernal的test里的makefile(调用abstract m的makefile从而编译出有运行时环境的程序)3.am里的makefile(编译出有运行时环境的程序的基本配置等)。这三个紧密联系,例如调用2的makefile(make ARCH=riscv32-nemu ALL=dummy run),会经过231的顺序编译运行该程序,也是就PA2.1熟悉的工作了。
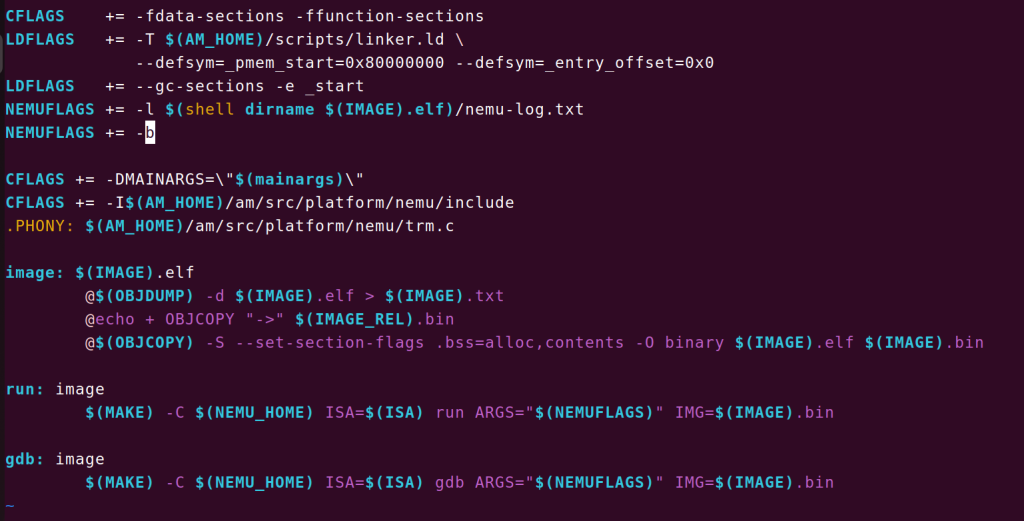
他说让我看makefile文件,我只是大致浏览了一下(仔细看对我的挑战太大了),我主要还是看的结果命令(make -nB),希望我之后能静下心看一下,虽然我只是简单的看了一下,但是做出他的必做题还是没有问题的,即

就是在/abstract-machine/script/platform/nemu.mk中加上NEMUFLAGS += -b,然后他就会传给nemu的makefile的ARGS变量并且运行
之后就是实现库函数了(其实你的linux系统里就有这些库函数的实现hhh,应该存在在一个libc.a文件中),话说我之前学c语言用的是K&R的书,里面很多课后练习就是实现各种各样的库函数,梦回暑假。
pa文档介绍了未定义行为(undefined behaviour),谈谈我的理解,首先,官方文档会定义很多东西,但也会存在一些东西未被定义,比如c语言就有很多未定义行为,比如除0,既然是未定义的,那么很多根据这个文档设计出来的东西对于同一个行为就存在不同的处理方式(毕竟你没告诉我怎么做嘛),这给编译器更大的自由去生成高效的指令,但如果程序员对ub理解不深,写出ub(或者检测ub)的代码时,就可能会被编译器优化掉,具体见apsys12.pdf (washington.edu),如果我们没有按照文档规范去实现一个东西,比如文档说要这样做,但你那样做了,那你这个那样做也是未定义的。
从状态机的视角来看,一个状态经过一个ub,另一个状态是不确定的。
实现库函数的过程并不困难,只要细心一点,看文档仔细一点,debug耐烦一点就行,最好写点注释,因为之后还得对sprintf添东西的。
基础设施
iringbuf
首先为什么需要iringbuf呢,log文件不就够了吗,我有些不理解,于是在qq群问了一下,老师的回答是:“因为你未必能看到log,试想你在跑一个很大的程序(其实不用很大)如果你把itrace全部写进log里,log可能会有好几G,并且io事务会大幅降低nemu运行速度”,我现在暂时没有遇到过这个问题所以不存在这种需求,经过老师的点拨我就明白了。
之后就是具体的实现了,实现之前,我一直看着源码不敢开始,因为我想我该把这些代码放哪里最合适,怎么样写最优雅,内耗了很久,实际上,我们要遵循KISS法则,不管三七二十一,一通乱加就好了,先把功能给跑起来再说优雅的事情,有了这一层思考,勇气就上来了
首先明确需求,我需要一个环形缓冲区(init),我需要在每次执行前把这条指令以及反汇编写入缓冲区中(write),并且我需要能打印出缓冲区的内容(print),根据这三个需求实现三个接口即可
写的过程对我稍有困难,因为这是我第一次写,不过也不算太难。
但是写完之后将其放在哪我纠结了很久,最后,我觉得因为在项目的始与终都需要这个环形缓冲区,所以我决定让所有文件都可操控iringbuf,于是我在src/cpu/下新写了一个iringbuf.c来装其实现,包括init,write,print,free几个接口,定义了一个全局变量结构IRingBuf,他在init函数被初始化,并通过几个接口来操作他,使得调用者无需关心IRingBuf变量究竟在哪,我是受了nemu的pmem数组的启发,pmem数组同样是如此的思想,之后我写了一个.h文件放在include/cpu/下,之后再在monitor.c的init_monitor函数中和其他功能一起被初始化 。因为生成汇编指令的操作是重复的(在写入log文件时也需要),我就将其封装到一个函数(record_inst())中,如下
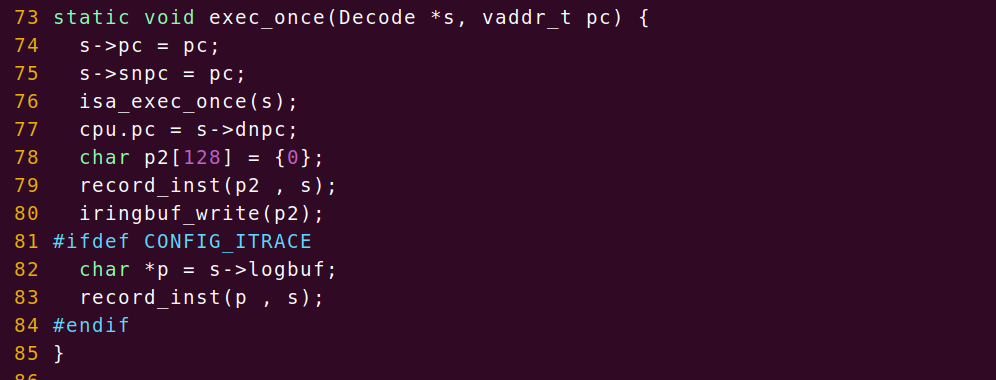
其实这有一点问题,假如在执行指令时出错了,就无法将这个出错的指令写入了,但是余老师是这么写的,要改也挺麻烦的(应该改在取完指令就写入,不能等到执行完写入),要改需要在isa相关的文件中修改,我也懒得改了。之后哪里出现bug退出就可以把iringbuf_print函数加在哪里。
mtrace
首先可以先修改kconfig,定义两个变量,MTRACE和MTRACE_COND,也就是和itrace是一样的,我的思路是定义一个记录memory trace的函数,将mtrace写入缓冲区,这个函数执行与否取决于MTRACE,是否将缓冲区写入log文件取决于MTRACE_COND,因为io的开销应该比较大的,按照文档所说即是:“另外也可以实现mtrace输出的条件, 例如你可能只会关心某一段内存区间的访问, 有了相关的条件控制功能, mtrace使用起来就更加灵活了.”
我顺便看了一下memory的代码,代码分为vaddr和paddr,virtual和physical的意思,我觉得所有指令都是用的vaddr的,并且余老师也是只将vaddr的操作暴露给了inst.c文件,那为什么讲义上说是在paddr_read函数中记录mtrace呢,或许我有些细节没注意到,还是余老师有意为之?这里多少有点不太理解。(之后想了一下,这个是为了调试的作用,应该把tracer放最底层的访存行为中以记录所有的访存行为从而方便调试)
写的过程就不说了,特别简单。
ftrace
ftrace首先需要读入一个ELF的文件,所以需要对ELF文件的一些基本的属性有一些了解,我之前有了解过但是有些忘了,趁此机会就再了解一遍,我通过手册来了解(man 5 ELF),手册中的内容和readelf的内容基本一一对应,可以两两对照的学习
1,首先是ELF header(Ehdr),包含elf文件的基本信息,其中也包含了phdr和shdr的offset
2,之后是program header(Phdr),是一系列的结构体,每个结构体描述了一个段(segment)或者是程序执行所需的信息。这些信息被操作系统用来准备程序的执行环境,和section的区别在于,segment是在内存中的布局的叫法,section是在elf文件中布局的叫法,一个segment包含一个或多个section
3,之后是section header(Shdr),是一系列的结构体,每个结构体描述了文件中的一个节(section)
4,之后是symbol table,是一系列的结构体,其中name属性包含了该符号在strtab的index,value包含了该符号的属性,比如function…
5,之后是string table,他是一个以null结尾的一堆字符串
知道这么多就可以了
之后还需要了解一些操作binary文件的函数,fread,fwrite,fseek,ftell,rewind
但是我还是第一次写这个,觉得还是没什么思路,不过好在我只是要提取出 1,所有的字符串本身 2,字符串对应于程序中的地址,所以,基本思路就是
1.在elf header中的e_shoff成员中找到section header的偏移,从而找到section header,其次还有几个和section相关的分别是,e_shentsize,e_shnum,e_shstrndx
2.在section table中通过e_shentsize,e_shnum精准找到sh_name为symtab和strtab的偏移
3.在symtab中,通过st_info提取type为FUNC的条目,在特定的条目中通过st_value来提取对应的地址,通过st_name来提取对应符号在strtab中的index
4.通过index,在strtab中找到相应的字符串,与上面的地址一一对应
至于如何存储这些数据,由于我还没有学过数据结构这门课,我能想到的就只有定义一个结构体数组。
ok,思路存在,开始coding
经过不懈努力以及google,终于是写完了,写完我数了数有77行,一个解析elf文件的函数有这么麻烦我也是没有想到的,代码我就不贴上来了
写完之后发现一件事,_start函数在symbol表中的size是0,我百思不得其解,于是在qq群问了一下,助教也很热心的回答了我,函数是在编译时被编译器识别成函数,并且标注这个函数的大小,但是_start函数存在于start.S文件中,并不是由编译器编译而成的指令,我去看了一看这个文件,在这个文件中,_start被显式的类型标记成了function,但是没有明确其大小,导致链接器不知道他的大小,于是我在start.s中显式的标注了其大小就可以了,感谢助教老师
接下来才是真正实现ftrace,之后发现那个递归的函数他的call和ret数量不一样,经过了解,是因为编译器对其进行了尾调用优化,也就是用的jr指令,不保存函数返回值的调用,长见识了属于是,至于怎么处理这个呢,我还没有想好,好在一般的ftrace是没有问题的,我就先暂时跳过了
测试你的klib
我一开始在这里遇见了一些问题,我想用argc和argv来控制测试的函数,可是我发现好像不行,运行不稳定,很多时候段错误,并且argc都是个很小的负数,我猜测不是我写的问题,是am可能还不支持argc和argv,所以我索性就每次都全部测试一遍。
PA2.3
串口
nemu中的串口实现就是你往串口的mmio地址写值的时候(一次只能写1 byte),调用串口的回调函数,实际上就是模拟真实硬件的数字电路部分,回调函数名字是serial_io_handler,他从寄存器(也就是模拟的mmio地址部分)中取值,然后将该值写到自己计算机的stderr输出流中
for example,putch的实现实际上就是一条指令sb a0,1016(a5) # a00003f8 <_end+0x1fff73f8>,一条store byte指令,nemu在执行这条指令时,先调用vaddr_write,再调用paddr_write,在这个函数中检测是调用pmem_write还是mmio_write(我终于知道paddr和pmem的区别了555),如果是后者则会调用相应的注册过的回调函数,也就是上面说的,最终写到屏幕上。
实现printf
文档提示中:“你之前已经实现了sprintf()了, 它和printf()的功能非常相似, 这意味着它们之间会有不少重复的代码. 你已经见识到Copy-Paste编程习惯的坏处了, 思考一下, 如何简洁地实现它们呢?”
个人的解读就是抽象两者之间相似的部分变成另一个stactic函数,实现安全的代码重用,我一开始的想法是就直接使用实现过的sprintf来先获得格式好的字符串再用putch来一个一个输出,但是,我在网上发现了别人写的一个特别奇妙的写法(不应该说特别奇妙,应该说我才看到过但完全不会使用),就是使用回调函数,回调函数实际上就是向一个函数传参但是传的不是数据,而是一种行为,一个行为就是putch,那另一个行为我自定义一个不就好了,太妙了,我早上刚了解的回调函数的概念,竟然下午就有一个绝佳的好机会进行实践,这其实也反映出你懂一个概念并不是真的掌握了他,因为你根本不知道他是怎么来的,所以你就不会再日常生活中去使用它,不去使用就等于没学
时钟
我想直接贴代码了,反正还是比较简单的,主要是要看懂代码,理解原理,需要注意需要先请求offset为4的位置
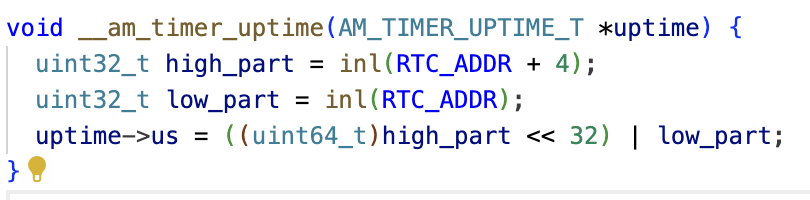
原理基本就是请求time部分的内存就从内存返回之前调用回调函数,如果从头开始讲就是,先程序层面调用io_read,ioread被编译成一条访存指令,请求time部分的内存就调用回调函数,回调函数初始化那部分的内存,那部分的内存先在nemu中返回,再被存在buf中从上面这个函数返回,由于是64位的,就需要两次访存再拼接即可,程序层面就获得了相应的值。这里的理解一定要基于硬件层面(nemu)和软件层面(am)之间去理解
键盘
预学习阶段做过数电版的键盘,于是简单的以为键盘就是通码断码是固定的,比如断码我记得有一个0x F0,这里想当然导致花了我一点时间,however,反应过来就好了,还是比较简单的,总的来说就是键盘通码和断码nemu有一套自己的数字,通过将SDL_sym(忘了叫啥了)通过数组坐标的形式映射至nemu中的数字,有点像python中的字典,源码里面有一个宏套宏的操作看起来好牛逼,虽然我学不会,源码就不贴了
VGA
写完了vga,但是之后再写这里